
When disaster strikes, a great recovery strategy is required. Oftentimes, deficiencies are only discovered when it’s already too late. Simplyblock provides comprehensive disaster recovery support for databases, file storages, and whole infrastructures, enabling the restore from ground up in a different availability zone with minimal RTO (Recovery Time Objective) and near-zero RPO (Recovery Point Objective).
Amazon EBS, Amazon S3, and Local Instance Storage
AWS’ cloud block storage ( Amazon EBS ) is a great product, providing a multitude of different product types depending on your performance (random IOPS, access latency) requirements. However, the provided durability is limited. Depending on the EBS volume type , AWS provides a durability indicator between 99.8% and 99.999%. The bigger issue though, in case of a disaster in your availability zone (AZ), storage will become unavailable in its entirety and, depending on the type of the disaster, data may actually be lost (partially or in full).
The durability is even worse with local instance storage. Local instance storage are NVMe disks which are physically located on the virtual machine host that runs your workload. That said, all data stored on local instance storage is immediately lost once the instance is turned off, or a failure occurs with the physical host.
Amazon S3 storage, on the other hand, is considered to be extremely durable, offering 99.999999999% durability. In addition, it is replicated across availability zones. Therefore, the probability of data loss by any kind of disaster is close to zero. To our knowledge, and as of time of writing, it has never actually happened. In terms of durability, Amazon S3 is king.We trade, however, durability for latency.
Data Protection for Amazon EBS
As shown, all persistent (meaning, non ephemeral) data stored in Amazon EBS requires additional means of protection. That said, the most common way to protect your data is taking a snapshot of your EBS volume and backing it up to Amazon S3.
Those S3 backups have a number of important drawbacks though: A snapshot-based backup always implicitly means that you’ll have data loss of some kind. Data which has been written between the last backup and the time of the failure is irrecoverably lost. No restore procedure will be able to recover it. For low velocity data (data which is rarely changed) that may be a minor issue. Examples of this kind of data may be media files or archived documents. However, the data loss can be catastrophic for other types of data such as transactional systems. Multiple backups between different systems aren’t consistent between each other. The backup of one database may not fit the backup of another database or a file repository. That said, after restoration the systems may have inconsistent data states and will not integrate correctly. Bringing a collection of systems with backups taken at different times back into a working state can be a massive manual effort. Sometimes it is even impossible. Backup management is a significant effort. To free up disk space, it is necessary to remove snapshots from EBS after moving them to S3. Furthermore, backups have to be configured with retention policies. The successful operations of taking backups must be monitored and backups have to be tested regularly to make sure it is possible to restore them successfully.
Last but not least, human error in backup management may lead to missing or corrupted backups.
Data Protection for Amazon EBS with Simplyblock
Simplyblock provides a smart solution to the consistent recovery of hot data after a major incident or even a zone-level disaster.
First and foremost, simplyblock logical volumes stores data synchronously into the hot tier storage backend. In addition, data is also written into an asynchronous replicated write-ahead log (WAL). Writing this log is optimized for high throughput to secondary (low IOPS) storage such as S3 or HDD pools (e.g. the Amazon EBS st2 service). Last but not least, the WAL is efficiently compacted at regular intervals to limit storage growth and optimize recovery times.
Simplyblock’s logical volumes inherently support snapshots. Due to the copy-on-write nature of simplyblock, snapshots are taken immediately and, together with the WAL, asynchronously replicated to S3.
Data recovery, on the other hand, restores all live volumes and snapshots in a fully consistent manner. The asynchronicity of the replication limits data loss to a few hundred milliseconds.
Disaster Recovery with Near-Zero RPO
The solution stores all “hot” data either in distributed instance storage or within gp3 pools, providing the necessary online performance of storage. At the same time, all data is also asynchronously replicated into S3.
In case of a loss of the entire infrastructure in an availability zone (including the gp3 volumes and local instance storage) it is possible to consistently bootstrap the entire environment in a new AZ.
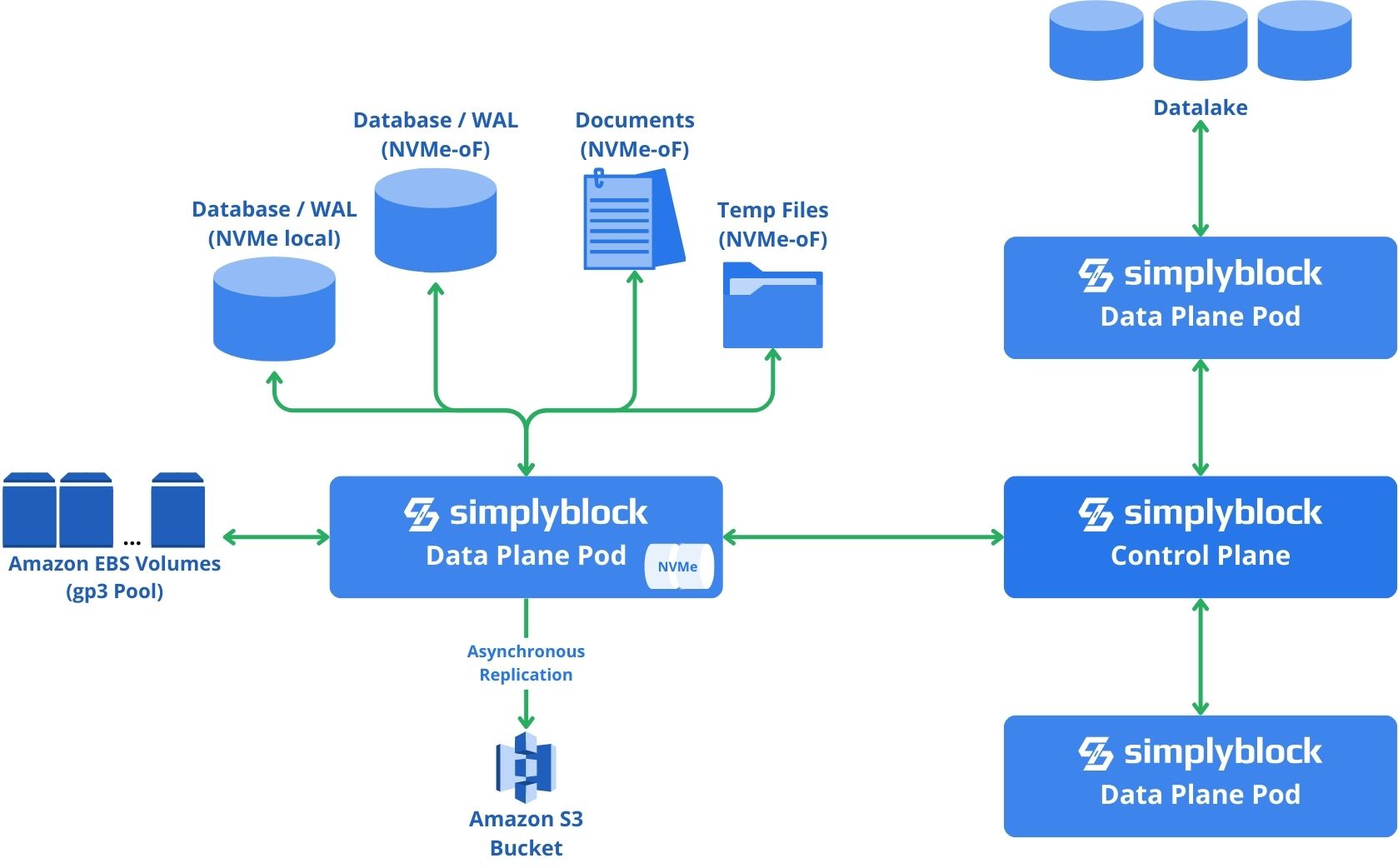
If a customer uses simplyblock to store the databases, but also bootstrap and deployment information (like ArgoCD configuration, terraform data, or similar), a recover operation can consistently restore the entirety of the infrastructure from ground up. Using this strategy, infrastructures supported by simplyblock can be consistently and fully automatically recovered with near-zero RPO and a low RTO becomes possible.
For this purpose, the “primary” simplyblock storage pod, which contains all data required for bootstrapping, has to be restarted in a new zone and connected to the control plane. Afterwards, all storage is consistently accessible.
First, infrastructure templates and configurations for the environment are retrieved, after which the deployment scripts are run and the infrastructure is redeployed. In this process, databases, documents, and other file stores can already be connected to their corresponding volumes, which contain all of the data in a crash-consistent manner.
At a later stage, “secondary” storage plane pods can be restarted within the new availability zone and data will be recovered.
The recovery time depends largely on the amount of data and the instance network bandwidth. The read time from S3 is highly optimized using large, parallel reads, wherever possible to pre-fetch hot data as quickly as possible.
Conclusion
All that said, simplyblock, the intelligent storage orchestrator, provides a powerful and feature-rich solution to provide a crash-consistent, yet performant storage solution.
Built upon well-known storage solutions, such as local instance storage, Amazon EBS, and Amazon S3, simplyblock combines the ultra low latency access of NVMe volumes (pooled or unpooled) with the extreme durability of Amazon S3. Simplyblock’s write-ahead log and disaster recovery support enables the lowest RPO and minimal downtime, even in case of the loss of a full availability zone.
Get started with simplyblock today and learn all about the other amazing features simplyblock brings right to you.
You can also explore our Simplyblock for AWS performance results for real-world benchmarks.


