AI Storage: How To Build Scalable Data Infrastructures for AI workloads?
Apr 30th, 2024 | 11 min read

Table Of Contents
- Understanding the Scale-Out Approaches in AI Storage
- Why AI Storage for Unstructured Data?
- Introducing Intelligent Data Infrastructure (IDI)
- Building Storage for the AI Era
- How can Organizations adopt Intelligent Data Infrastructure as AI Storage?
- How can Simplyblock help to build a Storage System for IDI?
- Questions and Answers
AI workloads bring new requirements to your AI storage infrastructure, marking a significant change compared to the “ML era” of Big Data storage. The average scale of an AI dataset is multiple times higher than ML data sets used in training. This triggers a question of whether the approach to data infrastructure needs to be revisited accordingly and with respect to the massive scale and performance requirements of AI workloads.
In this article, we explore the impact of unstructured data on data volumes. We’ll emphasize the shift from ML to AI. Finally, we underscore the significance of a forward-looking data architecture for businesses aiming to be data-first in the era of AI. Scale-out storage infrastructure plays a key role in this process. We will put that in the context of Intelligent Data Infrastructure (IDI).

Understanding the Scale-Out Approaches in AI Storage
Scale-up approaches keep adding more resources like CPU, RAM, and storage to existing servers. While traditional data centers rely heavily on such scale-up architecture, modern AI workloads demand vertical and horizontal scaling capabilities. Scale-out architecture involves adding more nodes to distribute the workload. It has become crucial for handling massive AI datasets. However, organizations need the flexibility to scale up individual nodes. Flexibility for performance-intensive workloads and to scale out their infrastructure to handle growing data volumes.
Comparing Scale Up vs Scale Out Approaches
Scale-up architecture focuses on increasing the capacity of existing nodes by adding more CPU, memory, and storage resources. This vertical scaling approach offers benefits like:
- Simpler management of fewer, more powerful nodes
- Lower network overhead and latency
- Better performance for single-threaded workloads
In contrast, scale-out architecture distributes workloads across multiple nodes, offering advantages such as:
- Linear performance scaling by adding nodes
- Better fault tolerance through redundancy
- More cost-effective growth using commodity hardware
For AI workloads, organizations often need both approaches—scaling up nodes for compute-intensive tasks like model training and scaling out storage and processing capacity for massive datasets. The key is finding the right balance based on specific workload requirements.
Why AI Storage for Unstructured Data?
One of the defining characteristics of the AI era is the exponential growth of unstructured data. It is estimated that even up to 95% of today’s data is unstructured. That means it is not considered “data” in the context of current data infrastructures. These are images, videos, text documents, social media feeds, and other types of “data” that aren’t used as a base for data-driven decision-making today. AI is changing that with its ability to convert unstructured data into structured data. AI models feed themselves with diverse data types that are invaluable for their training, yet they also pose a significant challenge in terms of storage, processing, and retrieval. All the data that nobody cared about in cold storage as of yesterday is now at the core of data infrastructure today.
Unstructured data, such as images and videos, tends to be larger in size compared to structured data. This exponential growth in data volumes strains traditional data infrastructure, necessitating more scalable solutions. It also comes in a myriad of formats and structures. Managing this complexity becomes critical for organizations. They aim to harness the insights buried within unstructured datasets. Data Infrastructure’s adaptability is indispensable in handling the variety and complexity inherent in unstructured data.
The Scale of Training Data
AI models that leverage unstructured data, especially in tasks like image recognition or natural language processing, require significant computational power. The demand for scalable compute resources becomes paramount, and the ability to dynamically allocate resources between storage and compute is key for efficiency at scale. Distinct from traditional Machine Learning (ML) datasets, these AI-scale datasets, in the realm of image recognition, natural language processing, and complex simulations, reach massive scales and often come with storage requirements in the hundreds of terabytes. Data infrastructure must be tailor-made for such workloads, enabling dynamic resource allocation and efficient management of these vast datasets.
Introducing Intelligent Data Infrastructure (IDI)
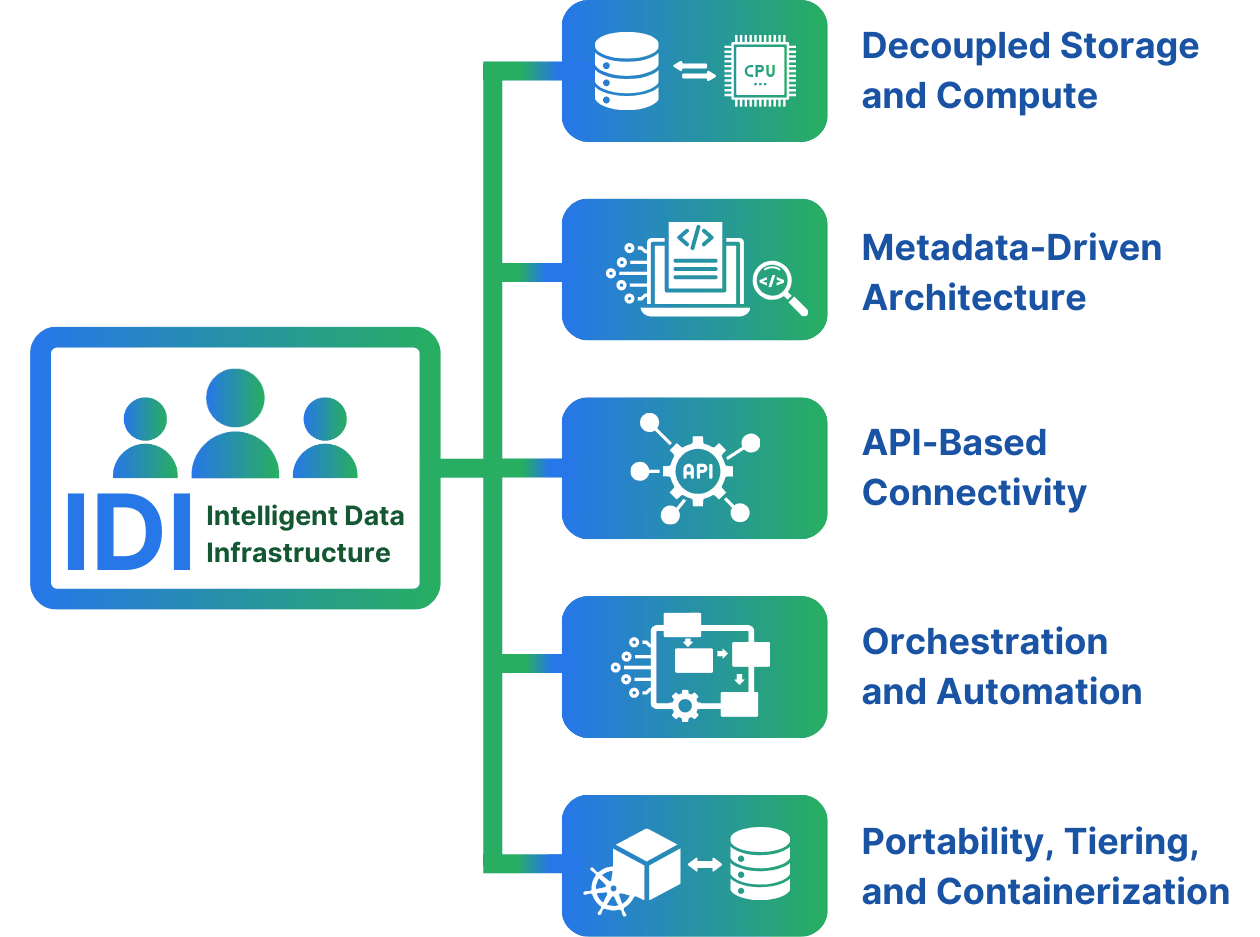
Intelligent Data Infrastructure (IDI) is a novel concept that reimagines how organizations handle and utilize their data. At its core, it involves decomposing traditional monolithic data systems into modular components that can be dynamically orchestrated to meet specific requirements. IDI can be built on public or private clouds, on-premises, or hybrid cloud scenarios. This modular, containerized, and fully portable approach enables organizations to build a data infrastructure that is not only scalable but also adaptable to the evolving needs of AI applications and businesses. The Intelligent Data Infrastructure (IDI) requires a few components to deliver its full potential.
Decoupled Storage and Compute
Intelligent Data Infrastructure (IDI) separates storage and compute resources, allowing organizations to scale each independently. This decoupling is particularly beneficial for AI workloads, where computational demands vary significantly. By allocating resources dynamically, organizations can optimize performance and cost-effectiveness.
Metadata-Driven Architecture
A metadata-driven architecture is crucial to Intelligent Data Infrastructures (IDI). Metadata provides essential information about the data. That makes it easier to discover, understand, and process. In the context of AI, where diverse datasets with varying structures are common, a metadata-driven approach enhances flexibility and facilitates efficient data handling. Storing and accessing large amounts of metadata might require the ability to scale IOPS without limitations to accommodate the unpredictability of the workloads. Today, IOPS limitations are a common problem faced by users of public clouds.
API-Based Connectivity
Intelligent Data Infrastructure (IDI) relies on APIs (Application Programming Interfaces) for seamless connectivity between different components. This API-centric approach enables interoperability and integration with various tools and platforms. This fosters a collaborative ecosystem for AI development.
Orchestration and Automation
Orchestration and automation are pivotal in Intelligent Data Infrastructure (IDI). By automating tasks such as data ingestion, processing, and model deployment, organizations can streamline their AI workflows and reduce the time-to-value for AI projects. Automation on the storage layer is key to cater to these requirements.
Portability, Tiering, and Containerization
Workload portability has never been better. But data portability (or data infrastructures) has yet to catch up. Kubernetes made it easy to orchestrate the movement of workloads. However, due to storage and data gravity, the most common use cases for Kubernetes are stateless workloads. The shift of stateful workloads into Kubernetes is consistent with the rise of Intelligent Data Infrastructure. Intelligent storage tiering further allows us to build data infrastructures in the most efficient and agnostic way.
Building Storage for the AI Era
Unlike traditional systems, Intelligent Data Infrastructure (IDI) is architected to handle the massive scale of AI datasets. The flexibility to both scale up individual nodes for performance-intensive workloads and scale out storage across multiple nodes. The ability to scale out storage horizontally and vertically, coupled with dynamic resource allocation, ensures optimal performance for AI workloads. Future-proofing data platforms is crucial in the fast-paced AI era. With its modular and adaptable design, Intelligent Data Infrastructure (IDI) enables organizations to stay ahead by easily integrating new technologies and methodologies as they emerge, ensuring longevity and relevance.
As AI becomes a driving force across industries, every business is poised to become a data and AI business. Intelligent Data Infrastructure (IDI) facilitates this transition by providing the flexibility and scalability needed by businesses to leverage data as a strategic asset. The modular nature of Intelligent Data Infrastructure (IDI) empowers organizations to adapt to evolving AI requirements. Whether integrating new data sources or accommodating changes in processing algorithms, A flexible approach to Infrastructure Management ensures agility in the face of dynamic AI landscapes.
Organizations can optimize infrastructure costs by decoupling storage and computing resources and dynamically allocating them as needed. This cost efficiency is particularly valuable in AI, where resource requirements can vary widely depending on the nature of the tasks at hand. While cloud services are becoming commoditized, the edge lies in how businesses build and optimize their data infrastructure. A unique approach to data management, storage, and processing can provide a competitive advantage, making businesses more agile, innovative, and responsive to the demands of the AI era.
How can Organizations adopt Intelligent Data Infrastructure as AI Storage?
In the era of AI, where unstructured data reigns supreme and businesses are transitioning to become data-first, the role of Intelligent Data Infrastructure (IDI) cannot be overstated. It addresses the challenges posed by the sheer volumes of unstructured data and provides a forward-looking foundation for businesses to thrive in AI. As businesses strive to differentiate themselves, a strategic focus on building a unique and scalable data infrastructure will undoubtedly be the key to gaining a competitive edge in the evolving world of artificial intelligence. The first step of adopting IDI in your organization should be identifying bottlenecks and challenges with the current data infrastructure. Some of the questions one should ask are:
- Is your current data infrastructure horizontally scalable?
- Do you face IOPS limits?
- Are you resorting to the use of sub-optimal storage services to save costs? (e.g., using object storage because it’s “cheap”)
- Can you scale out storage and compute resources without scaling storage or vice versa?
- Based on workload demands, can your infrastructure scale up (add resources to existing nodes) and scale out (add new nodes)?
- Can you easily and efficiently migrate data and workloads between clouds and environments?
- What is the level of automation in your data infrastructure?
- Do you use intelligent data services (such as deduplication and automatic resource balancing) to decrease your organization’s data storage requirements?
Organizations following the traditional approaches to data infrastructures would not be able to answer these questions easily, which by itself would be a warning sign that they are far from adopting IDI. As always, awareness of the problem needs to come first. At simplyblock, we help you adopt an intelligent data infrastructure without the burden of re-architecting everything, providing drop-in solutions to boost your data infrastructure with the sight of the AI era.
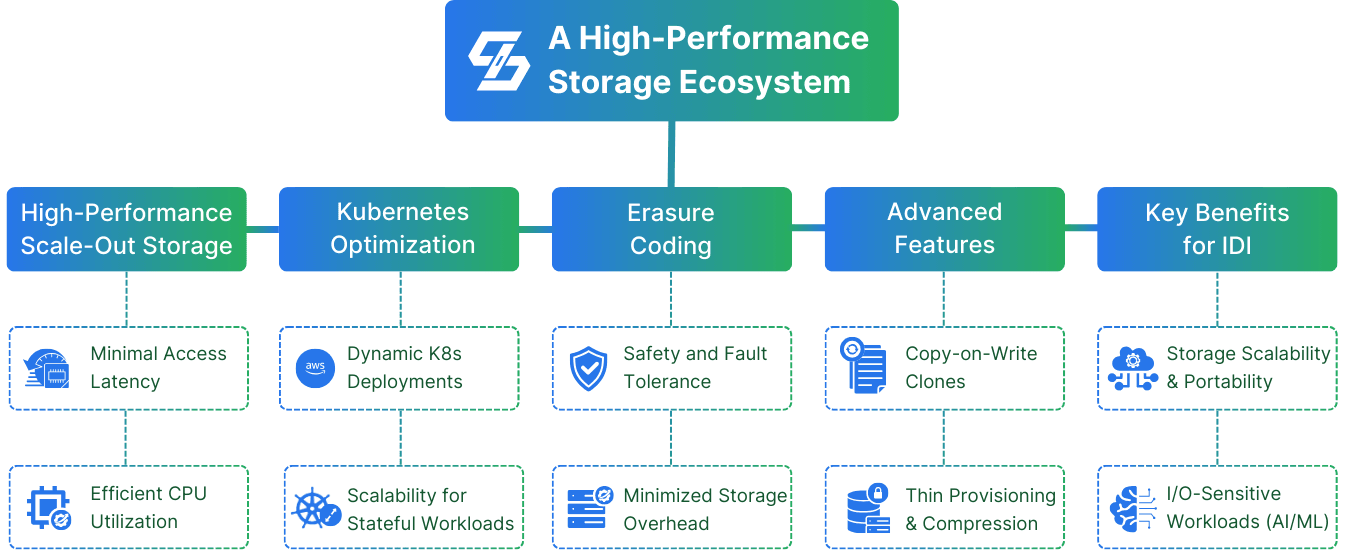
How can Simplyblock help to build a Storage System for IDI?
Simplyblock’s high-performance scale-out storage clusters are built upon EC2 instances with local NVMe disks. Our technology uses NVMe over TCP for minimal access latency, high IOPS/GB, and efficient CPU core utilization, surpassing local NVMe disks and Amazon EBS in cost/performance ratio at scale. Ideal for high-performance Kubernetes environments, simplyblock combines the benefits of local-like latency with the scalability and flexibility necessary for dynamic AWS EKS deployments, ensuring optimal performance for I/O-sensitive workloads like databases. Using erasure coding (a better RAID) instead of replicas helps to minimize storage overhead without sacrificing data safety and fault tolerance.
Additional features such as instant snapshots (full and incremental), copy-on-write clones, thin provisioning, compression, encryption, and many more, make simplyblock the perfect solution that meets your requirements before you set them. Get started using simplyblock right now, or learn more about our feature set.
Questions and Answers
Scale-out storage enables horizontal expansion of storage nodes to handle increasing AI data volumes. It provides high throughput and low latency required for training large models, especially in distributed environments using GPUs or TPUs.
AI/ML training generates massive read/write operations on large datasets. Standard storage can become a bottleneck, whereas high-performance block storage like NVMe over TCP ensures fast access, reduced training time, and better GPU utilization.
Simplyblock provides software-defined storage with NVMe over TCP, delivering high IOPS, low latency, and easy scalability. It supports dynamic provisioning and encryption, making it ideal for AI pipelines on Kubernetes or VMs.
Use fast block storage for training data, separate metadata layers, ensure redundancy, and scale linearly across nodes. Integrating a CSI-compatible SDS like simplyblock allows AI teams to provision and scale volumes automatically.
Yes. Simplyblock integrates natively with Kubernetes, offering persistent volumes for AI jobs. It’s built for performance-intensive workloads like computer vision, NLP, and generative models, helping teams scale seamlessly in hybrid or cloud-native environments.


