
Table Of Contents
- Understanding the Data-in-Use, Data-in-Transit, and Data-at-Rest
- Criticality of Data Protection
- Understanding Data At Rest Encryption (DARE)
- Key Management Solutions
- Implementing Data At Rest Encryption (DARE)
- Linux Data At Rest Encryption with dm-crypt and LUKS
- Data At Rest Encryption with Kubernetes
- Data At Rest Encryption with Simplyblock
- Best Practices for Securing Data at Rest
- Data At Rest Encryption: The Essential Component of Data Management
- Questions and Answers
TLDR: Data At Rest Encryption (DARE) is the process of encrypting data when stored on a storage medium. The encryption transforms the readable data (plaintext) into an encoded format (ciphertext) that can only be decrypted with knowledge about the correct encryption key.
Today, data is the “new gold” for companies. Data collection happens everywhere and at any time. The global amount of data collected is projected to reach 181 Zettabytes (that is 181 billion Terabytes) by the end of 2025. A whopping 23.13% increase over 2024.
That means data protection is becoming increasingly important. Hence, data security has become paramount for organizations of all sizes. One key aspect of data security protocols is data-at-rest encryption, which provides crucial protection for stored data.

Understanding the Data-in-Use, Data-in-Transit, and Data-at-Rest
Before we go deep into DARE, let’s quickly discuss the three states of data within a computing system and infrastructure.
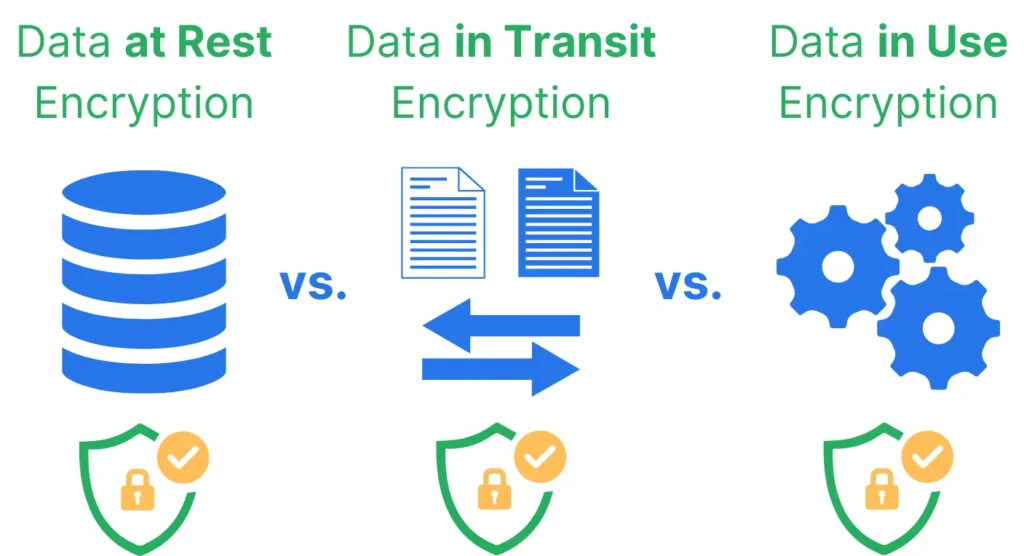
To start, any type of data is created inside an application. While the application holds onto it, it is considered as data in use. That means data in use describes information actively being processed, read, or modified by applications or users.
For example, imagine you open a spreadsheet to edit its contents or a database to process a query. This data is considered “in use.” This state is often the most vulnerable as the data must be in an unencrypted form for processing. However, technologies like confidential computing enable encrypted memory to process even these pieces of data in an encrypted manner.
Next, data in transit describes any information moving between locations. Locations means across the internet, within a private network, or between memory and processors. Examples include email messages being sent, files being downloaded, or database query results traveling between the database server and applications—all examples of data in transit.
Last but not least, data at rest refers to any piece of information stored physically on a digital storage media such as flash storage or hard disk. It also considers storage solutions like cloud storage, offline backups, and file systems as valid digital storage. Hence, data stored in these services is also data at rest. Think of files saved on your laptop’s hard drive or photos stored in cloud storage such as Google Drive, Dropbox, or similar.
Criticality of Data Protection
For organizations, threats to their data are omnipresent. Starting from unfortunate human error, deleting important information, coordinated ransomware attacks, encryption of your data, and asking for a ransom to actual data leaks.
Especially with data leaks, most people think about external hackers copying data off of the organization’s network and making it public. However, this isn’t the only way data is leaked to the public. There are many examples of Amazon S3 buckets without proper authorization, databases being accessible from the outside world, or backup services being accessed.
Anyhow, organizations face increasing threats to their data security. Any data breach has consequences, which are categorized into four segments:
- Financial losses from regulatory fines and legal penalties
- Damage to brand reputation and loss of customer trust
- Exposure of intellectual property to competitors
- Compliance violations with regulations like GDPR, HIPAA, or PCI DSS
While data in transit is commonly protected through TLS (transport layer encryption), data at rest encryption (or DARE) is often an afterthought. This is typically because the setup isn’t as easy and straightforward as it should be. It’s this “I can still do this afterward” effect: “What could possibly go wrong?”
However, data at rest is the most vulnerable of all. Data in use is often unprotected but very transient. While there is a chance of a leak, it is small. Data at rest persists for more extended periods of time, giving hackers more time to plan and execute their attacks. Secondly, persistent data often contains the most valuable pieces of information, such as customer records, financial data, or intellectual property. And lastly, access to persistent storage enables access to large amounts of data within a single breach, making it so much more interesting to attackers.
Understanding Data At Rest Encryption (DARE)
Simply spoken, Data At Rest Encryption (DARE) transforms stored data into an unreadable format that can only be read with the appropriate encryption or decryption key. This ensures that the information isn’t readable even if unauthorized parties gain access to the storage medium.
That said, the strength of the encryption used is crucial. Many encryption algorithms we have considered secure have been broken over time. Encrypting data once and taking for granted that unauthorized parties can’t access it is just wrong. Data at rest encryption is an ongoing process, potentially involving re-encrypting information when more potent, robust encryption algorithms are available.
Available Encryption Types for Data At Rest Encryption
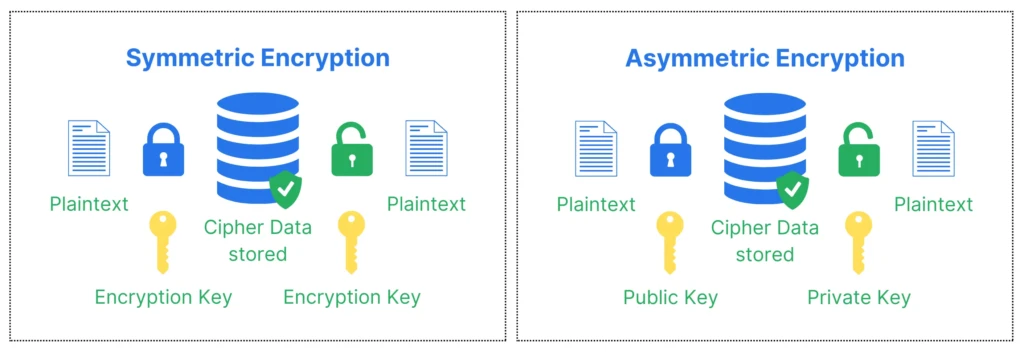
Two encryption methods are generally available today for large-scale setups. While we look forward to quantum-safe encryption algorithms, a widely adopted solution has yet to be developed. Quantum-safe means that the encryption will resist breaking attempts from quantum computers.
Anyhow, the first typical type of encryption is the Symmetric Encryption. It uses the same key for encryption and decryption. The most common symmetric encryption algorithm is AES, the Advanced Encryption Standard.
const cipherText = encrypt(plaintext, encryptionKey);
const plaintext = decrypt(cipherText, encryptionKey);
The second type of encryption is Asymmetric Encryption. Hereby, the encryption and decryption routines use different but related keys, generally referred to as Private Key and Public Key. According to their names, the public key can be publicly known, while the private key must be kept private. Both keys are mathematically connected and generally based on a hard-to-solve mathematical problem. Two standard algorithms are essential: RSA (the Rivest–Shamir–Adleman encryption) and ECDSA (the Elliptic Curve Digital Signature Algorithm). While RSA is based on the prime factorization problem, ECDSA is based on the discrete log problem. To go into detail about those problems is more than just one additional blog post, though.
const cipherText = encrypt(plaintext, publicKey);
const plaintext = decrypt(cipherText, privateKey);
Encryption in Storage
The use cases for symmetric and asymmetric encryption are different. While considered more secure, asymmetric encryption is slower and typically not used for large data volumes. Symmetric encryption, however, is fast but requires the sharing of the encryption key between the encrypting and decrypting parties, making it less secure.
To encrypt large amounts of data and get the best of both worlds, security and speed, you often see a combination of both approaches. The symmetric encryption key is encrypted with an asymmetric encryption algorithm. After decrypting the symmetric key, it is used to encrypt or decrypt the stored data.
Simplyblock provides data-at-rest encryption directly through its Kubernetes CSI integration or via CLI and API. Additionally, simplyblock can be configured to use a different encryption key per logical volume for the highest degree of security and muti-tenant isolation.
Key Management Solutions
Next to selecting the encryption algorithm, managing and distributing the necessary keys is crucial. This is where key management solutions (KMS) come in.
Generally, there are two basic types of key management solutions: hardware and software-based.
For hardware-based solutions, you’ll typically utilize an HSM (Hardware Security Module). These HSMs provide a dedicated hardware token (commonly a USB key) to store keys. They offer the highest level of security but need to be physically attached to systems and are more expensive.
Software-based solutions offer a flexible key management alternative. Almost all cloud providers offer their own KMS systems, such as Azure Key Vault, AWS KMS, or Google Cloud KMS. Additionally, third-party key management solutions are available when setting up an on-premises or private cloud environment.
When managing more than a few encrypted volumes, you should implement a key management solution. That’s why simplyblock supports KMS solutions by default.
Implementing Data At Rest Encryption (DARE)
Simply said, you should have a key management solution ready to implement data-at-rest encryption in your company. If you run in the cloud, I recommend using whatever the cloud provider offers. If you run on-premises or the cloud provider doesn’t provide one, select from the existing third-party solutions.
DARE with Linux
As the most popular server operating system, Linux has two options to choose from when you want to encrypt data. The first option works based on files, providing a filesystem-level encryption.
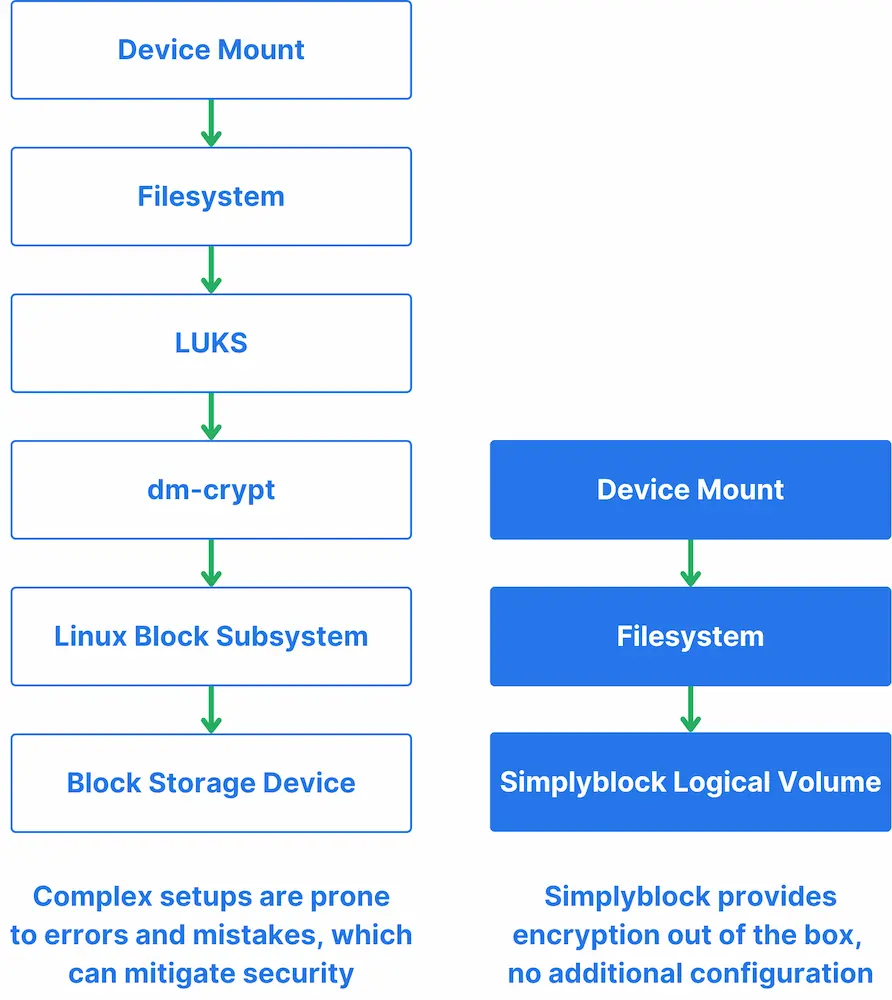
Typical solutions for filesystem-level based encryption are eCryptfs, a stacked filesystem, which stores encryption information in the header information of each encrypted file. The benefit of eCryptfs is the ability to copy encrypted files to other systems without the need to decrypt them first. As long as the target node has the necessary encryption key in its keyring, the file will be decrypted. The alternative is EncFS, a user-space filesystem that runs without special permissions. Both solutions haven’t seen updates in many years, and I’d generally recommend the second approach.
Block-level encryption transparently encrypts the whole content of a block device (meaning, hard disk, SSD, simplyblock logical volume, etc.). Data is automatically decrypted when read. While there is VeraCrypt, it is mainly a solution for home setups and laptops. For server setups, the most common way to implement block-level encryption is a combination of dm-crypt and LUKS, the Linux Unified Key Setup.
Linux Data At Rest Encryption with dm-crypt and LUKS
The fastest way to encrypt a volume with dm-crypt and LUKS is via the cryptsetup tools.
Debian / Ubuntu / Derivates:
sudo apt install cryptsetup
RHEL / Rocky Linux / Oracle:
yum install cryptsetup-luks
Now, we need to enable encryption for our block device. In this example, we assume we already have a whole block device or a partition we want to encrypt.
Warning: The following command will delete all data from the given device or partition. Make sure you use the correct device file.
cryptsetup -y luksFormat /dev/xvda
I recommend always running cryptsetup with the -y parameter, which forces it to ask for the passphrase twice. If you misspelled it once, you’ll realize it now, not later.
Now open the encrypted device.
cryptsetup luksOpen /dev/xvda encrypted
This command will ask for the passphrase. The passphrase is not recoverable, so you better remember it.
Afterward, the device is ready to be used as /dev/mapper/encrypted. We can format and mount it.
mkfs.ext4 /dev/mapper/encrypted
mkdir /mnt/encrypted
mount /dev/mapper/encrypted /mnt/encrypted
Data At Rest Encryption with Kubernetes
Kubernetes offers ephemeral and persistent storage as volumes. Those volumes can be statically or dynamically provisioned.
For pre-created and statically provisioned volumes, you can follow the above guide on encrypting block devices on Linux and make the already encrypted device available to Kubernetes.
However, Kubernetes doesn’t offer out-of-the-box support for encrypted and dynamically provisioned volumes. Encrypting persistent volumes is not in Kubernetes’s domain. Instead, it delegates this responsibility to its container storage provider, connected through the CSI (Container Storage Interface).
Note that not all CSI drivers support the data-at-rest encryption, though! But simplyblock does!
Data At Rest Encryption with Simplyblock
Due to the importance of DARE, simplyblock enables you to secure your data immediately through data-at-rest encryption. Simplyblock goes above and beyond with its features and provides a fully multi-tenant DARE feature set. That said, in simplyblock, you can encrypt multiple logical volumes (virtual block devices) with the same key or one key per logical volume.
The use cases are different. One key per volume enables the highest level of security and complete isolation, even between volumes. You want this to encapsulate applications or teams fully.
When multiple volumes share the same encryption key, you want to provide one key per customer. This ensures that you isolate customers against each other and prevent data from being accessible by other customers on a shared infrastructure in the case of a configuration failure or similar incident.
To set up simplyblock, you can configure keys manually or utilize a key management solution. In this example, we’ll set up the key manual. We also assume that simplyblock has already been deployed as your distributed storage platform, and the simplyblock CSI driver is available in Kubernetes.
First, let’s create our Kubernetes StorageClass for simplyblock. Deploy the YAML file via kubectl, just as any other type of resource.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: encrypted-volumes
provisioner: csi.simplyblock.io
parameters:
encryption: "True"
csi.storage.k8s.io/fstype: ext4
... other parameters
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
Secondly, we generate the two keys. Note the results of the two commands down.
openssl rand -hex 32 # Key 1
openssl rand -hex 32 # Key 2
Now, we can create our secret and Persistent Volume Claim (PVC).
apiVersion: v1
kind: Secret
metadata:
name: encrypted-volume-keys
data:
crypto_key1:
crypto_key2:
–--
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
simplybk/secret-name: encrypted-volume-keys
name: encrypted-volume-claim
spec:
storageClassName: encrypted-volumes
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 200Gi
And we’re done. Whenever we use the persistent volume claim, Kubernetes will delegate to simplyblock and ask for the encrypted volume. If it doesn’t exist yet, simplyblock will create it automatically. Otherwise, it will just provide it to Kubernetes directly. All data written to the logical volume is fully encrypted.
Best Practices for Securing Data at Rest
Implementing robust data encryption is crucial. In the best case, data should never exist in a decrypted state.
That said, data-in-use encryption is still complicated as of writing. However, solutions such as Edgeless Systems’ Constellation exist and make it possible using hardware memory encryption.
Data-in-transit encryption is commonly used today via TLS. If you don’t use it yet, there is no time to waste. Low-hanging fruits first.
Data-at-rest encryption in Windows, Linux, or Kubernetes doesn’t have to be complicated. Solutions such as simplyblock enable you to secure your data with minimal effort.
However, there are a few more things to remember when implementing DARE effectively.
Data Classification
Organizations should classify their data based on sensitivity levels and regulatory requirements. This classification guides encryption strategies and key management policies. A robust data classification system includes three things:
- Sensitive data identification: Identify sensitive data through automated discovery tools and manual review processes. For example, personally identifiable information (PII) like social security numbers should be classified as highly sensitive.
- Classification levels: Establish clear classification levels such as Public, Internal, Confidential, and Restricted. Each level should have defined handling requirements and encryption standards.
- Automated classification: Implement automated classification tools to scan and categorize data based on content patterns and metadata.
Access Control and Key Management
Encryption is only as strong as the key management and permission control around it. If your keys are leaked, the strongest encryption is useless.
Therefore, it is crucial to implement strong access controls and key rotation policies. Additionally, regular key rotation helps minimize the impact of potential key compromises and, I hate to say it, employees leaving the company.
Monitoring and Auditing
Understanding potential risks early is essential. That’s why it must maintain comprehensive logs of all access to encrypted data and the encryption keys or key management solutions. Also, regular audits should be scheduled for suspicious activities.
In the best case, multiple teams run independent audits to prevent internal leaks through dubious employees. While it may sound harsh, there are situations in life where people take the wrong path. Not necessarily on purpose or because they want to.
Data Minimization
The most secure data is the data that isn’t stored. Hence, you should only store necessary data.
Apart from that, encrypt only what needs protection. While this sounds counterproductive, it reduces the attack surface and the performance impact of encryption.
Data At Rest Encryption: The Essential Component of Data Management
Data-at-rest encryption (DARE) has become essential for organizations handling sensitive information. The rise in data breaches and increasingly stringent regulatory requirements make it vital to protect stored information. Additionally, with the rise of cloud computing and distributed systems, implementing DARE is more critical than ever.
Simplyblock integrates natively with Kubernetes to provide a seamless approach to implementing data-at-rest encryption in modern containerized environments. With our support for transparent encryption, your organization can secure its data without any application changes. Furthermore, simplyblock utilizes the standard NVMe over TCP protocol which enables us to work natively with Linux. No additional drivers are required. Use a simplyblock logical volume straight from your dedicated or virtual machine, including all encryption features.
Anyhow, for organizations running Kubernetes, whether in public clouds, private clouds, or on-premises, DARE serves as a fundamental security control. By following best practices and using modern tools like Simplyblock, organizations can achieve robust data protection while maintaining system performance and usability.
But remember that DARE is just one component of a comprehensive data security strategy. It should be combined with other security controls, such as access management, network security, and security monitoring, to create a defense-in-depth approach to protecting sensitive information.
That all said, by following the guidelines and implementations detailed in this article, your organization can effectively protect its data at rest while maintaining system functionality and performance.
As threats continue to evolve, having a solid foundation in data encryption becomes increasingly crucial for maintaining data security and regulatory compliance.
Questions and Answers
Data At Rest Encryption (DARE), or encryption at rest, is the encryption process of data when stored on a storage medium. The encryption transforms the readable data (plaintext) into an encoded format (ciphertext) that can only be decrypted with knowledge about the correct encryption key.
Data-at-rest refers to any piece of information written to physical storage media, such as flash storage or hard disk. This also includes storage solutions like cloud storage, offline backups, and file systems as valid digital storage.
Data-in-use describes any type of data created inside an application, which is considered data-in-use as long as the application holds onto it. Hence, data-in-use is information actively processed, read, or modified by applications or users.
Data-in-transit describes any information moving between locations, such as data sent across the internet, moved within a private network, or transmitted between memory and processors.


