Avoiding Storage Lock-in: Block Storage Migration with Simplyblock
Aug 27th, 2024 | 7 min read

Storage and particularly block storage is generally easy to migrate. It doesn’t create vendor lock-in, which is very different from most database systems. Therefore, it’s worth to briefly line out where this difference comes from.
Why is Vendor Lock-In Dangerous?
For most companies, data is the most crucial part of their business. Therefore, it is dangerous to forfeit the control on how to store this incredibly important good and storage vendor lock-in poses a significant risk to these businesses. When a company becomes overly reliant on a single storage provider or technology, it can find itself trapped in an inflexible situation with far-reaching consequences.
The dangers of vendor lock-in manifest in several ways:
- Limited flexibility when requirements change or scalability needs grow.
- Potential cost increases when vendors decide for sudden price rise, knowing that customers depend on their services and migration is complicated or tortuous.
- Innovation constraints where other vendors provide advanced features.
- Data migration challenges when moving large amounts of data from one system to another which can be complex and expensive.
- Reduced bargaining power due to limited alternatives and complex migrations.
- Business continuity risks if a vendor faces issues or goes out of business.
- Compatibility problems due to proprietary formats or API which limited interoperability and compatibility.
These factors can lead to increased operational costs, decreased competitiveness, and potential disruptions to business continuity. As such, it’s crucial for organizations to carefully consider their storage strategies and implement measures to mitigate risks of vendor lock-in.
Migrating Block Storage on Linux
The interfaces provided by a database system are extremely complex compared to block storage. While some of it is standardized in SQL, there are a lot of system specifics in data and administrative interfaces. Migrating a database system from one to another—or even upgrading a release—requires entire projects.
On the other hand, the block storage interface on Linux is extremely simple in its essence, it allows you to write, read, or delete (trim) a range of blocks. The NVMe protocol itself is a bit more complicated, but is fully standardized (industry standard, managed by NVM Express, Inc.) and the majority of advanced features are neither required nor used. Most commonly they aren’t even accessible through the Linux block storage interface.
In essence, to migrate block storage under Linux, just follow a few simple steps, which have to be performed volume-by-volume: Take your volume offline Create your new volume of the same size or larger Copy or replicate the data on block-level (under Linux just use dd) Potentially resize the filesystem (if necessary) Verify the results In some cases, it is even possible to lower or eliminate the down-time and perform online replication. For example, the Linux Volume Manager (LVM) provides a feature to move data between physical volumes for a particular logical volume under the hood and while the volume is online (pvmove).
When operating in a Kubernetes-based environment, this simple migration is still perfectly available when using file or block storage.
Migration to Simplyblock
Migrating from any block storage to a simplyblock logical volume (virtual NVMe block device) is simple and supported through sbcli (the simplyblock command line interface).
Plain Linux
Within a plain linux environment, it is possible to use sbcli migrate with an input of a list of block storage volumes. The necessary and corresponding simplyblock logical volumes are created first. Those volumes may be of the same size or larger. The source volumes are then unmounted, and volume level replication takes place. Finally, source volumes may be deleted and replicated volumes are mounted instead.
Kubernetes
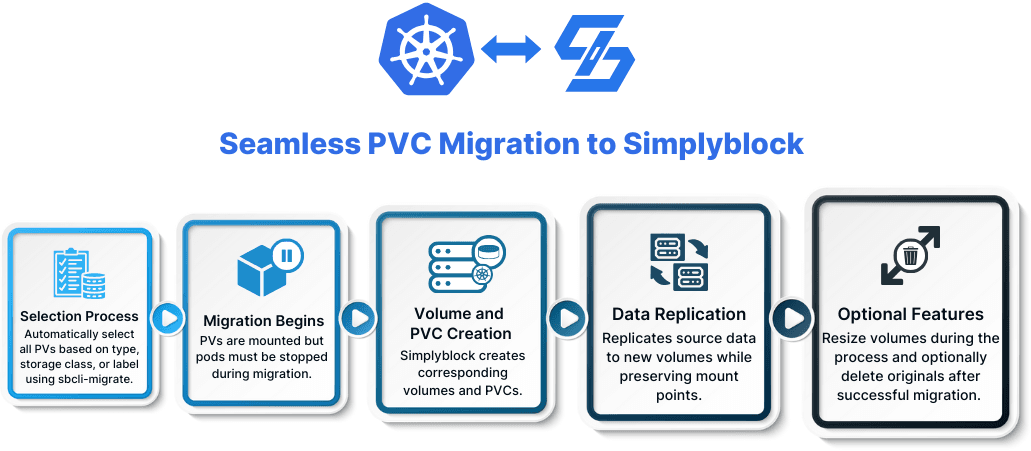
To migrate existing PVCs (Persistent Volume Claim) from any underlying storage, we need to first replicate them into simplyblock. Simplyblock’s internal Kubernetes job sbcli ‑ migrate can automatically select all PVs (Persistent Volume) of a particular type, storage class, or label. During the migration, PVCs may still be active, meaning that PVs can be mounted, but pods must be stopped.
Simplyblock will then create corresponding volumes and PVCs. Afterwards it will replicate the source’s content over to the new volumes, and deploy them under the same mount points.
Optionally, it is possible to resize the volumes during this process and to automatically delete the originals when the process finishes successfully.
Migration from Simplyblock
Migrating a specific volume away from simplyblock is just as easy. Outside of Kubernetes, using dd is the easiest way with the source and destination volumes being unmounted and just copied.
Inside a Kubernetes environment, the process of migrating block and file storage is straight-forward, too.
Individual PVs can simply be backed up after deleting the PVC. Make sure that the lifecycle of the PV and PVC aren’t bound, otherwise the PV will be deleted by Kubernetes in the process. Afterwards, the PV can be restored to new volumes and eventually re-mounted as a new PVC.
Velero is a tool that greatly helps to simplify this process.
Simplyblock: Storage without Vendor Lock-in
Utilizing block storage brings the best of all worlds. Easy migration options, compatibility due to standardized interfaces, and the possibility to choose the best tool for the job by mixing different block storage options.
Simplyblock embraces the fact that there is no one-fits-all solution and enables full interoperability and compatibility with the default standard interfaces in modern computing systems, such as block storage and the NVMe protocol. Hence, simplyblock’s logical volumes provide an easy migration path from and to simplyblock.
However, simplyblock logical volumes provide additional features that make users want to stay.
Simplyblock volumes are full copy-on-write block storage devices which enable immediate snapshots and clones. Those can be used for fast backups, or to implement features such as database branching, enabling fast turn-around times when implementing customer facing functionality.
Furthermore, multi-tenancy (including encryption keys per volume) and thin provisioning enable storage virtualization with overprovisioning. Making use of the fact that a typical storage utilization is around 30% brings down bundled storage requirements by 70% and provides a great way to optimize for cost efficiency. Additional features such as deduplication can decrease storage needs even further.
All this and more makes simplyblock, the intelligent storage orchestrator, the perfect storage solution for database operators and everyone who operates stateful Kubernetes workloads that require high performance and low latency block or file storage.
Questions and Answers
Storage lock-in happens when an organization becomes dependent on a specific vendor’s storage solution, making it difficult or costly to switch providers. This can limit flexibility, inflate costs, and hinder performance upgrades. Platforms like simplyblock help break free from vendor lock-in with open, portable, and standards-based block storage.
With modern solutions like simplyblock, it’s possible to migrate block storage in live environments using features like synchronous replication and seamless device switching. This approach ensures minimal or zero downtime for workloads running in Kubernetes, VMs, or bare metal.
Yes, simplyblock supports both NVMe over TCP and iSCSI to offer full flexibility for migrating legacy systems and deploying modern, high-performance environments. You can start with iSCSI and later switch to NVMe/TCP as your infrastructure evolves.
Software-defined storage (SDS) platforms like simplyblock decouple hardware from software, enabling better scalability, automation, and cloud-native integration. It’s ideal for environments like Kubernetes and modern on-premise private cloud environments, where flexibility and performance are key
Simplyblock uses CSI integration to provide Kubernetes-native storage, allowing dynamic provisioning, encryption, and seamless migration between devices. This eliminates manual intervention and supports modern DevOps workflows.


