
Table Of Contents
If you have services running in the AWS, you’ll eventually need block storage to store data. Services like Amazon EBS (Elastic Block Storage) provide block storage to be used in your EC2 instances, Amazon EKS (Elastic Kubernetes Services), and others. While providing an easy to use, and fast option, there are several limitations you’ll eventually run into.
Amazon EBS: the Limitations
When building out a new system, quick iterations are generally key. That includes fast turnovers to test ideas, or validate approaches. Using out of the box services, like Amazon EBS helps with these requirements. Cloud providers like AWS offer these services to get customers started quickly.
That said, cloud block storage volumes, such as Amazon EBS (gp3, io2, io2 Block Express), provide fast storage with high IOPS, and low latency for your compute instances (Amazon EC2) or Kubernetes environments (Amazon EKS or self-hosted) in the same availability zones.
While quick to get started, eventually you may run into the following shortcomings, which will make scaling either complicated or expensive.
Limited Free IOPS: The number of free IOPS is limited on a per volume basis, meaning that if you need high IOPS numbers, you have to pay extra. Sometimes you even have to change the volume type (gp3 only supports up to 16k IOPS, whereas io2 Block Express supports up to 256k IOPS).
Limited Durability: Depending on the selected volume type you’ll have to deal with limited data durability and availability (e.g. gp3 offers only 99.9% availability). There is no way to buy your way out of it, except using two volumes with some RAID1 like configuration.
No Thin Provisioning: Storage cost is paid per provisioned capacity per time unit and not by actual usage (which is around 50% less). When a volume is created, the given capacity is used for calculating the price, meaning if you create a 1TB volume but only use 100GB, you’ll still pay for the 1TB.
Limited Capacity Scalability: While volumes can be grown in size, you can only increase the capacity once every 6h (at least on Amazon EBS). Therefore, you need to estimate upfront how large the volume will grow in that time frame. If you miscalculated, you’ll run out of memory.
No Replication Across Availability Zones: Volumes cannot be replicated across availability zones, limiting the high availability if there are issues with one of the availability zones. This can be mitigated using additional tools, but they invoke additional cost.
Missing Multi-Attach: Attaching a volume to multiple compute instances or containers offers shared access to a dataset. Depending on volume-type, there is no option to multi-attach a volume to multiple instances.
Limited Latency: Depending on volume type, the access latency of a volume is located in the single or double-digit milliseconds range. Latency may also fluctuate. With low and predictable latency requirements, you may be limited here.
Simplyblock, Elastic Block Storage for the Cloud-Age
Simplyblock is built from the ground up to break-free of the typical cloud limitations and provide sub-millisecond predictable latency, virtually unlimited IOPS, while empowering you with scalability and a minimum five9s (99.999%) availability.
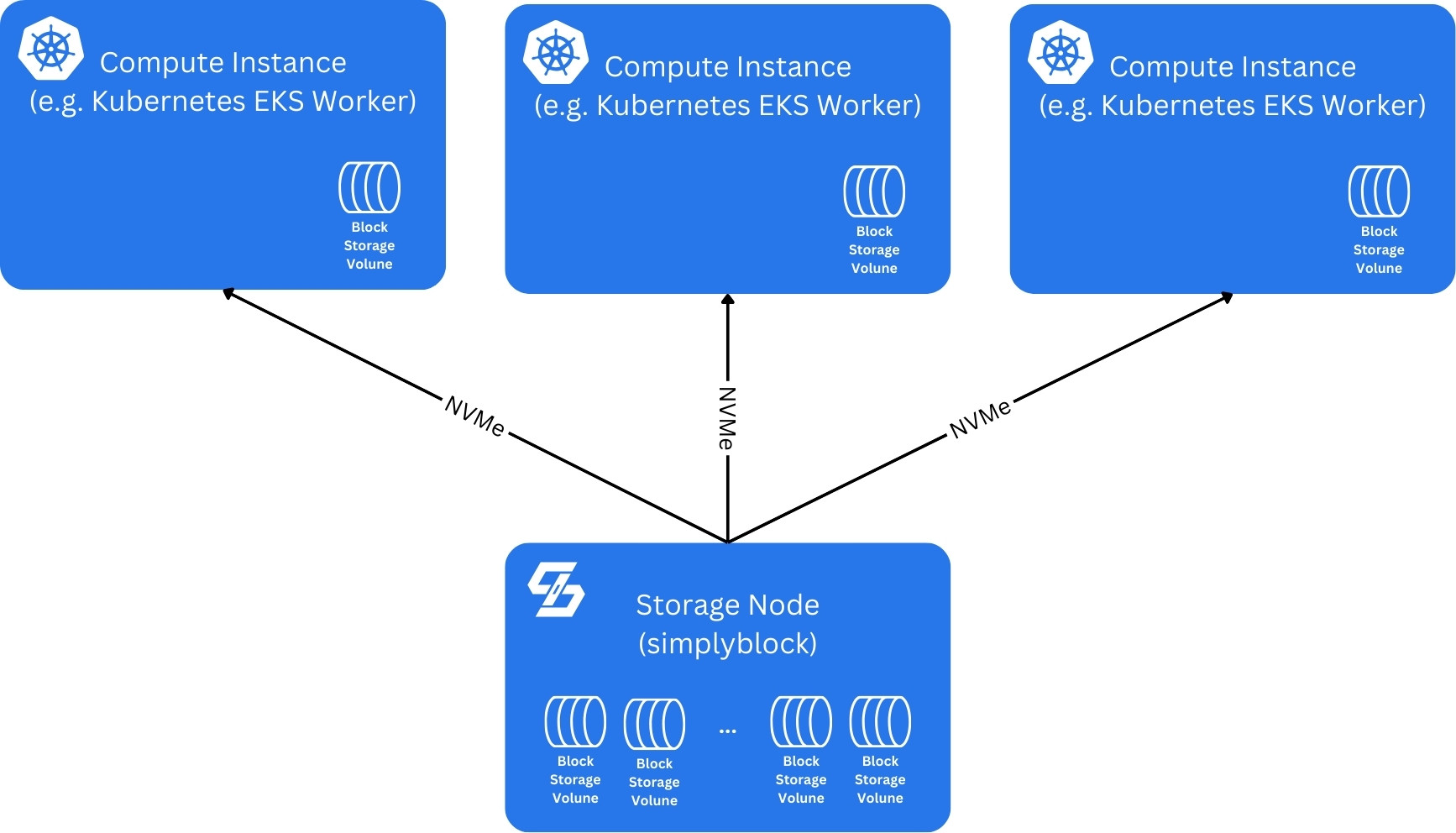
To overcome your typical cloud block storage service limitations, simplyblock implements a transparent and dynamic pooling of cloud-based block storage volumes, combining the individual drives into one large storage pool.
In its simplest form, block storage is pooled in a single, but separated storage node (typically a virtual machine). From this pooled storage, which can be considered a single, large virtual disk (or stripe), we carve out logical volumes. These logical volumes can differ in capacity and their particular performance characteristics (IOPS, throughput). All logical volumes are thin-provisioned, thus making more efficient use of raw disk space available to you.
On the client-side, meaning Linux and Windows, no additional drivers are required. Simplyblock’s logical volumes are exported as NVMe devices and use the NVMe over Fabrics industry standard for fast SSD storage, hence the NVMe initiator protocol for NVMe over TCP is already part of the operating system kernels on Linux and the latest versions of Windows Server. Simplyblock logical volumes are designed for ease of use and the out of the box experience, simply by partitioning them and formatting them with any operating-system specific file system.
Additional data services include instant snapshotting of volumes (for fast backup) and instant cloning (for speed and storage efficiency) as well as storage replication across availability zones (for disaster recovery purposes). All of this is powered by the copy-on-write nature of the simplyblock storage engine.
Last but not least, logical volumes can also be multi-attached to multiple compute instances.
More importantly though, simplyblock has its own Kubernetes CSI driver for automated container storage lifecycle management under the Kubernetes ecosystem.
Scaling out the Simplyblock Storage Pool
If the processing power of a single storage node isn’t sufficient anymore, or high-availability is required, you will use a cluster. When operating as a cluster, multiple storage nodes are combined as a single virtual storage pool and compute instances are connected to all of them.
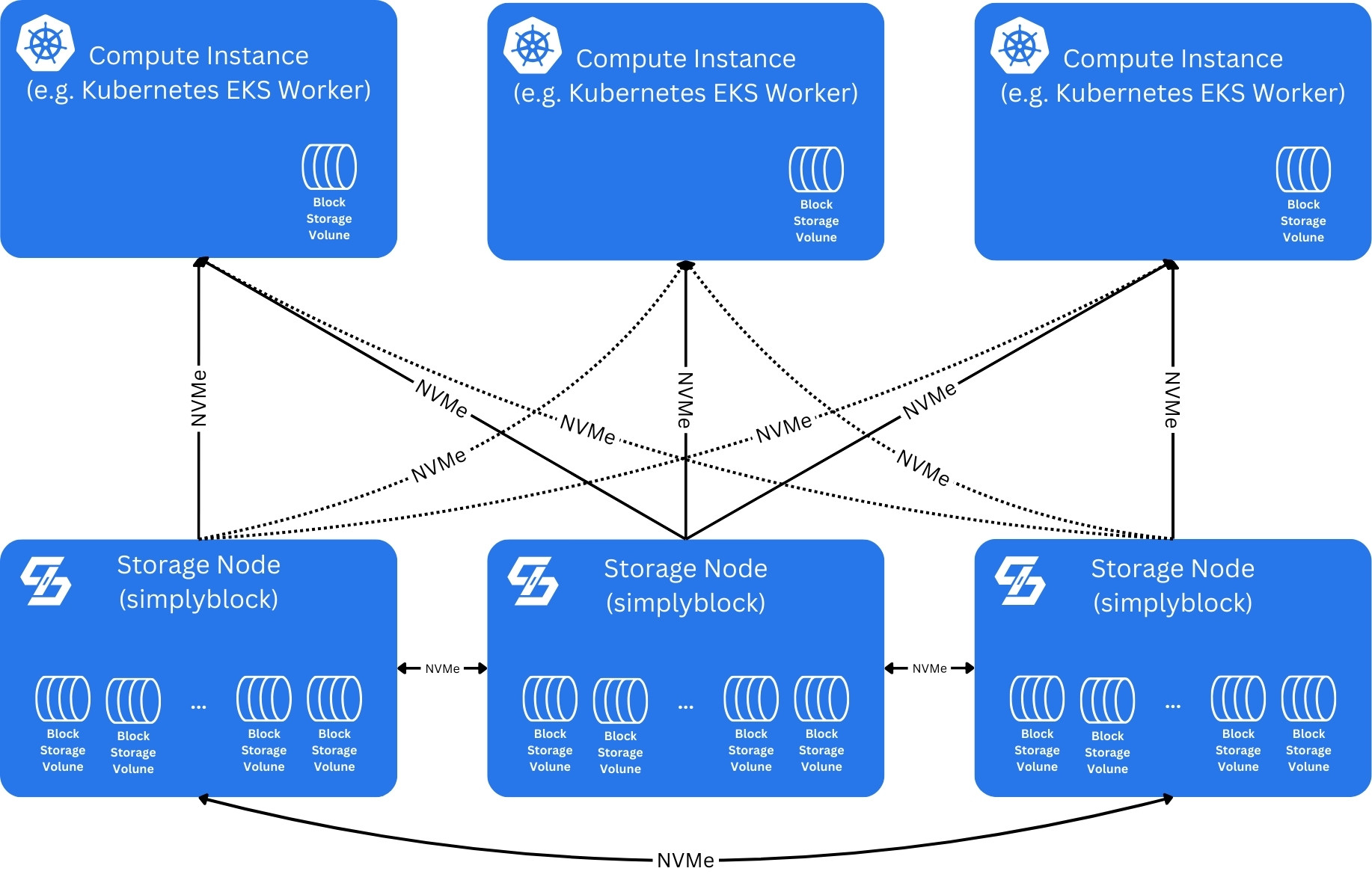
In this scenario, a transparent online fail-over mechanism takes care of switching the connection of logical volumes from one node to another in case of connection issues. This mechanism (NVMe multi-pathing with ANA) is already built into the operating system kernels of Linux and Windows Server, therefore, no additional software is required on the clients.
It is important to note that clusters can be expanded by either increasing the attached block storage pools (on the storage nodes) or by adding additional storage nodes to the cluster. This expansion can happen online, doesn’t require any downtime, and eventually results in an automatically re-balanced storage cluster (background operation).
Simplyblock and Microsecond Latency
When double-digit microsecond latency is required, simplyblock can utilize client-local NVMe disks as caches.
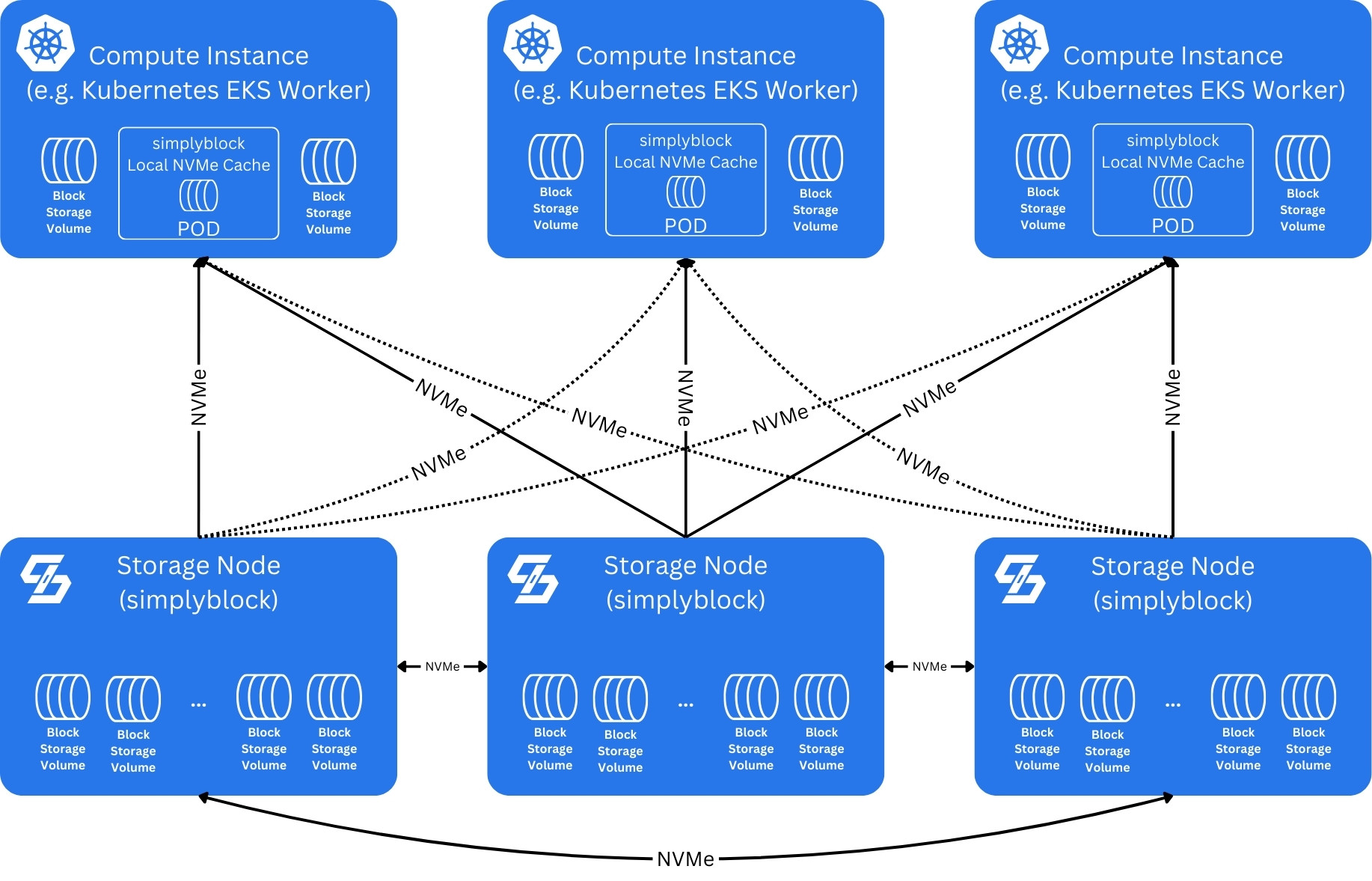 In this case simplyblock can boost read IOPS and decrease read access latency to below 100 microseconds. To achieve this you configure the local NVMe devices as a write-through (read) cache. Simplyblock client-local caches are deployed as containers. In a typical Kubernetes environment, this is done as part of CSI driver deployment via the helm chart. Caches are transparent to the compute instances and containers and look like any access to a local NVMe storage. They are, however, managed as part of the simplyblock cluster.
In this case simplyblock can boost read IOPS and decrease read access latency to below 100 microseconds. To achieve this you configure the local NVMe devices as a write-through (read) cache. Simplyblock client-local caches are deployed as containers. In a typical Kubernetes environment, this is done as part of CSI driver deployment via the helm chart. Caches are transparent to the compute instances and containers and look like any access to a local NVMe storage. They are, however, managed as part of the simplyblock cluster.
Simplyblock as Hyper-converged instead of Disaggregated
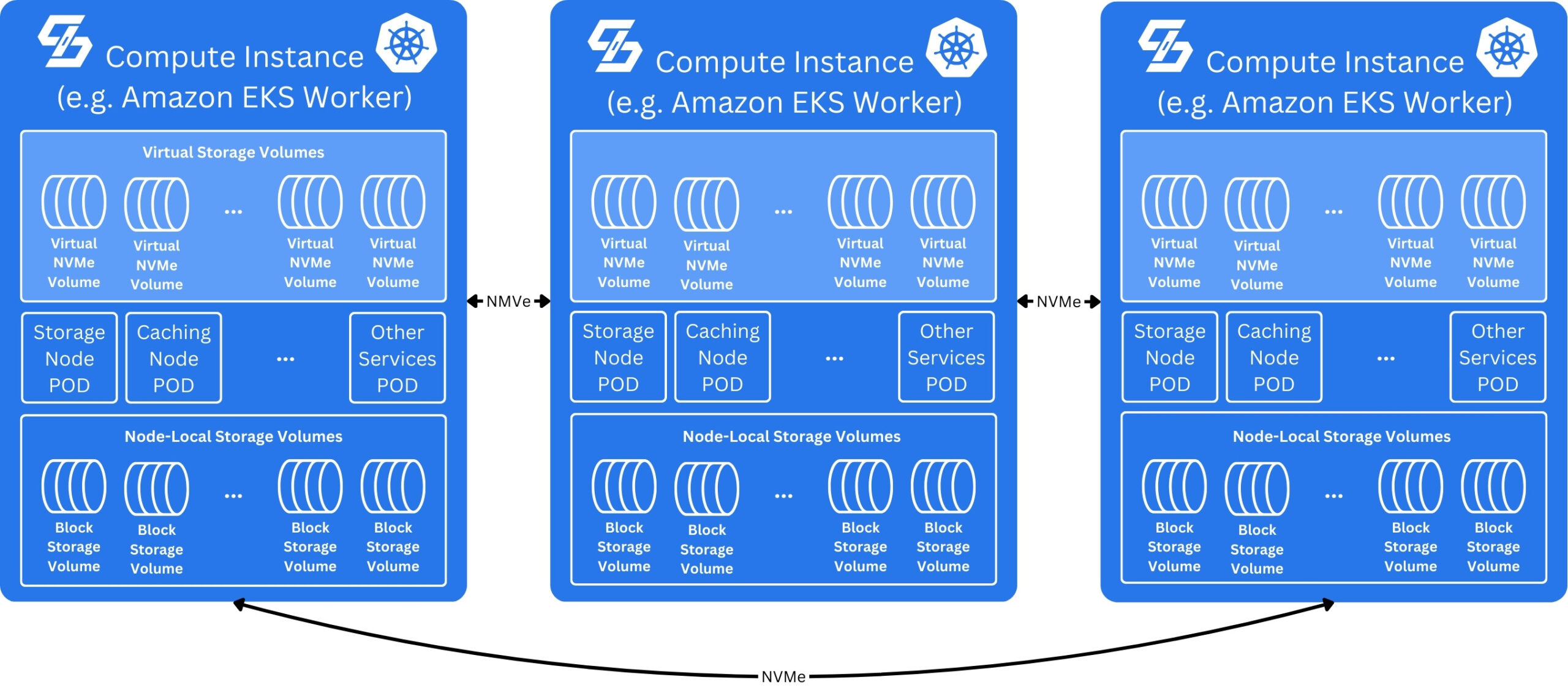
If you have sufficient spare capacity (CPU, RAM resources) on your compute instances and don’t want to deploy additional, separated storage nodes, a hyper-converged setup can be chosen as well. A hyper-converged setup is more cost-efficient as no additional virtual server is required.
On the other hand, resources are shared between services consuming storage and the simplyblock storage engine. While this is isn’t necessarily a problem, it requires some additional capacity planning on your end. Simplyblock generally recommends a disaggregated setup where storage and compute resources are strictly separated.
Simplyblock: Scalable Elastic Block Storage Made Easy
No matter what deployment strategy you choose, storage nodes are connected to simplyblock’s the hosted and managed control plane. The control plane is highly scalable and can serve thousands of storage clusters. That said, if you deploy multiple clusters, the management infrastructure is shared between all of them.
Likewise, all of the shown deployment options are realized using different deployment configurations of the same core components. Additionally, none of the configurations requires special software on the client side.
Anyhow, simplyblock enables you to build your own elastic block storage, overcoming the shortcomings of typical cloud provider offered services, such as Amazon EBS. Simplyblock provides advantages as overcome the (free) IOPS limit with a single volumes benefitting from 100k or more free IOPS (compared to e.g. 3,000 for aws gp3) reach read access latency lower than 100 microseconds multi-attach a volume to many instances replicate a volume across availability zones (synchronous and asynchronous replication) and bring down the cost of capacity / increase storage efficiency by multiple times via thin provisioning and copy-on-write clones scale the cluster according to your needs with zero downtime cluster extension
If you want to learn more about simplyblock see why simplyblock, or do you want to get started right away ?
Questions and Answers
Block storage volume pooling combines multiple storage volumes into a single pool, allowing dynamic provisioning, better utilization with thin provisioning, and simplified management. It’s ideal for environments that demand flexibility, such as Kubernetes or VM-based deployments.
Pooling reduces overprovisioning by allocating storage on demand from a shared resource. Instead of assigning fixed sizes upfront, volume pooling lets you scale based on real usage—leading to better cloud cost optimization.
Yes. When combined with a CSI-compatible software-defined storage like simplyblock, volume pooling enables dynamic, on-the-fly provisioning for persistent volumes, supporting high-density, multi-tenant environments with minimal manual intervention.
Pooled volumes can be intelligently distributed across NVMe-backed devices, improving IOPS, throughput, and resilience. Simplyblock enhances performance by integrating pooling with NVMe over TCP and smart data placement algorithms.
Absolutely. With platforms like simplyblock, pooled volumes still support full data-at-rest encryption, instant snapshots, and replication—ensuring no tradeoff between efficiency and enterprise-grade features.


