Choosing the Right Kubernetes Storage Solution for Your Workloads
Feb 19th, 2025 | 16 min read

Table Of Contents
- The Basics of Kubernetes Storage
- Understanding Storage Types and Their Impact
- Exploring Kubernetes Storage Solutions
- Deployment Environments
- Hyper-Coverged or Disaggregated
- Data Protection and Availability: Beyond Basic Backups
- Performance Considerations
- Security: A Multi-layered Approach
- Cost Optimization: Beyond Price Per Gigabyte
- Management and Operations
- Implementation: From Theory to Practice
- Future-Proofing Your Storage Strategy
- Making an Informed Decision
- Questions and Answers
TLDR: Choosing the right Kubernetes Storage isn’t easy. As a guideline for the selection, make sure you have the best of hyper-converged (co-located) and disaggregated setups. Also, make sure that your selected Kubernetes storage solution provides support for data encryption at rest and the necessary scalability for your growing use cases. As a rule of thumb, the most important factors are the deployment environment, the deployment model, the performance requirements, data protection, cost, and ongoing operation complexity.
Storage in Kubernetes isn’t just an afterthought—it’s the backbone of any stateful application. Imagine running a high-traffic database without persistent storage or deploying an AI model that loses its training data on every pod restart. Sounds like a nightmare, right? Kubernetes itself is stateless by design, but real-world applications often need their data to stick around. That’s where Kubernetes storage solutions come in.
Selecting the right storage for your cluster can be overwhelming. Do you go with a managed cloud option, a self-hosted distributed storage system, or something lightweight and simple? The answer isn’t always clear-cut, but by the end of this guide, you’ll have a much better idea of which storage solution is right for your workload(s).
The Basics of Kubernetes Storage
Kubernetes storage comes in a variety of different types. Each option catered to different application needs. Most applications need blazing-fast block storage, while others thrive on flexible, shared file storage. Last but not least, object storage is commonly used for backups and archives.
Choosing between these storage types depends largely on what you’re running. Databases, for example, demand block storage with low latency and high IOPS. Monitoring systems and log aggregators, on the other hand, are better suited to object or file storage that can scale horizontally.
Beyond just performance, storage solutions also vary in how they handle redundancy, availability, security, and management. A good storage solution should seamlessly integrate with Kubernetes while meeting your performance and compliance needs.
Understanding Storage Types and Their Impact
Storage in Kubernetes isn’t one-size-fits-all. Each type of storage serves distinct purposes and understanding these differences forms the foundation of making the right choice for your applications.
Block storage provides the foundation for most high-performance applications in Kubernetes. When your application needs direct disk access with minimal latency, block storage offers the most straightforward path. Database systems particularly benefit from block storage’s direct access nature, as it allows them to implement their own optimized data access patterns and caching mechanisms.
File storage brings a different set of capabilities to the table. By providing shared file system access across multiple pods, it enables collaboration and shared data access that many applications require. Development teams often find file storage invaluable for sharing code, configuration files, and other resources across multiple components of their application stack. However, some block storage solutions, such as simplyblock, enable shared (read-write) access to their block volumes, too.
Object storage rounds out the trinity of storage types in Kubernetes. Its HTTP-accessible nature makes it perfect for storing large amounts of unstructured data. Modern applications increasingly rely on object storage for everything from backup and archival to content delivery and big data analytics. The most commonly known access protocol (and kind of synonym) for object storage is S3.
📝 Editor’s Note: Simplyblock’s unified storage platform seamlessly integrates these storage types through intelligent tiering. This integration provides a single management plane while optimizing both cost and performance across your entire storage infrastructure.
Exploring Kubernetes Storage Solutions
Now that we understand what we need from storage, let’s dive into some of the best Kubernetes storage solutions available today.
Cloud Provider Storage Options
If you’re running Kubernetes on a major cloud provider, the easiest route is often to leverage their built-in storage solutions. These include Amazon EBS for AWS, Google Persistent Disks for Google Cloud, Azure Managed Disks for Microsoft Azure. In addition, pretty much all other cloud providers, such as DigitalOcean, provide managed block storage.
While these are seamlessly integrated and work great out-of-the-box, they can be costly as you scale or don’t scale to your requirements. They also tend to lock you into their respective ecosystems, which might not be ideal if you’re running a multi-cloud strategy. For businesses facing these challenges, Block Storage Migration provides a structured approach to transitioning storage while maintaining flexibility and avoiding vendor lock-in.
Open-Source and On-Prem Storage Solutions
If you’re looking for flexibility or running Kubernetes on-prem, open-source storage systems might be a better fit.
- Ceph RBD: A highly scalable, distributed block storage system.
- GlusterFS: Great for shared, distributed file storage.
- Longhorn: A lightweight, easy-to-deploy block storage system tailored for Kubernetes.
Open-source is commonly a great solution, especially for home-labs. For enterprise deployments, you want to make sure that the selected solution has enterprise-level support. Open-source solutions are often backed by companies which provide such support offerings.
Simplyblock – Modern Storage for Kubernetes
or a modern, Kubernetes-native approach to block storage, simplyblock is a compelling choice. It provides:
- High-performance block storage that integrates seamlessly with Kubernetes and provides full support for dynamic provisioning.
- Built-in snapshots, clones, and backup mechanisms to safeguard your data.
- Erasure coding to protect data from disks or node failures with distributed parity information (better RAID).
- Strong security features, including RBAC and encryption at rest.
- Streaming write-ahead log (WAL) backups to S3-compatible storage for point-in-time recovery.
📝 Editor’s Note: If you want a storage solution that makes backups and disaster recovery easy, Simplyblock’s WAL streaming capability is a game-changer.
Deployment Environments
The environment where you deploy your storage solution fundamentally impacts its effectiveness and heavily influences your storage decisions.
In cloud environments, native storage integration capabilities play a crucial role. Cloud providers offer their own storage solutions optimized for their infrastructure, but, as discussed before, this convenience often comes with the risk of vendor lock-in. Organizations must weigh the benefits of native integration against the potential costs of being tied to a specific cloud provider.
On-premises deployments present their own unique challenges. Hardware compatibility becomes paramount, and organizations must carefully consider their existing infrastructure’s capabilities. Network infrastructure particularly demands attention, as storage performance often depends heavily on network capacity and reliability.
The hybrid and multi-cloud approach has gained significant traction as organizations seek to balance flexibility with optimal resource utilization. In these environments, maintaining consistent storage interfaces across different platforms becomes crucial. Data mobility between environments must be seamless, and management tools must provide unified visibility and control across the entire infrastructure.
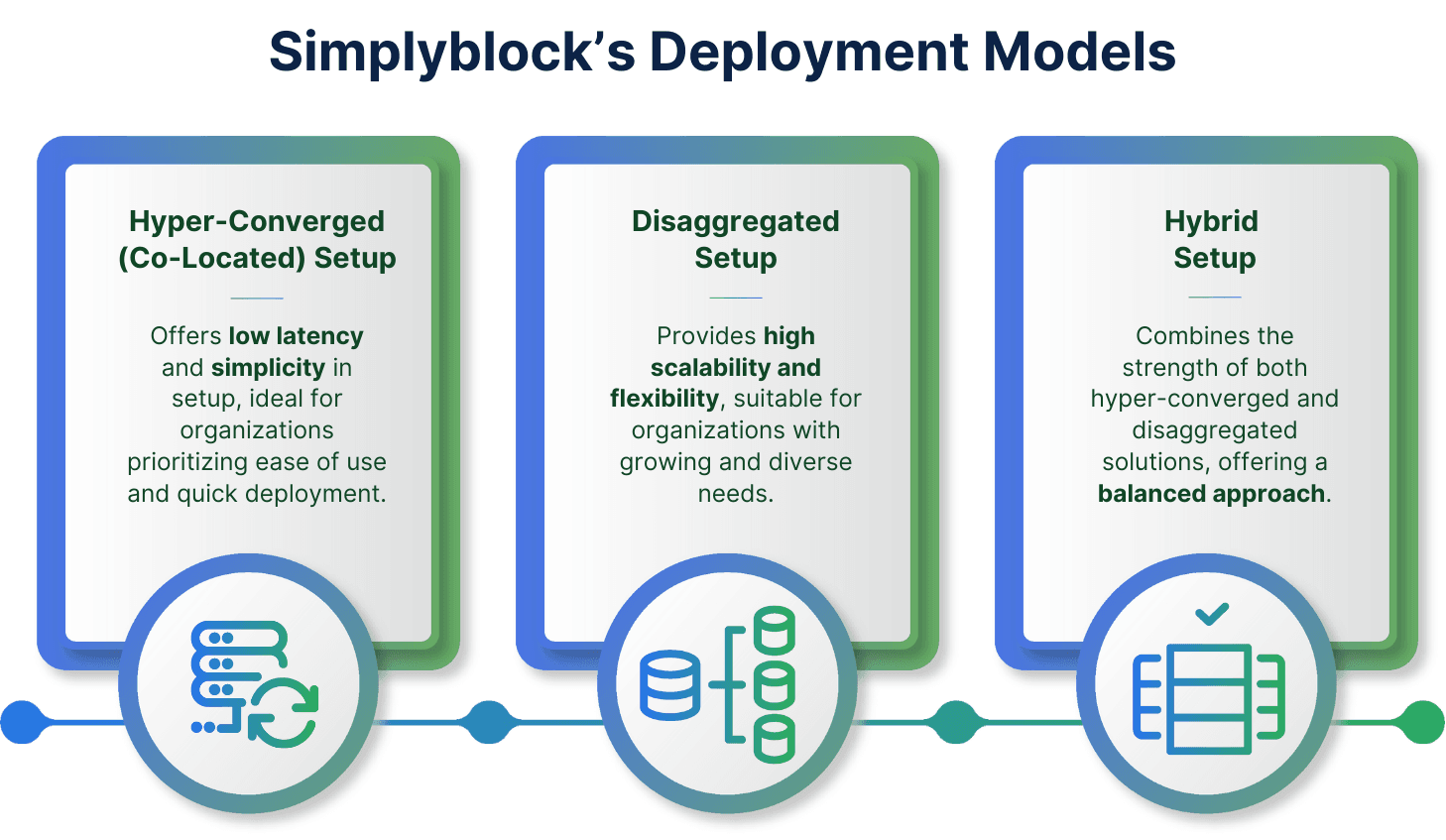
Hyper-Coverged or Disaggregated
Another important factor is the deployment model. Self-hosted solutions are available in two basic deployment options, hyper-converged (or co-located) and disaggregated.
Hyper-Converged (Co-Located)
Hyper-converged deployments sharing the same resources between your Kubernetes workloads and its storage. That means, that your storage solution is deployed co-located with your workload on the same machine. This enables the lowest possible latency, as the disk is local and most commonly non, or just a very thin software layer stands between your I/O operation and the actual storage device.
Some hyper-converged solutions use replication to other nodes to provide data protection in case of a node failure. Others, however, just provide a convenient way to use local storage via integration with LVM or ZFS. If you need data protection, make sure to select an option with any kind of distributed storage.
Hyper-converged setups tend to have issues with scalability since storage and compute are interlocked. Especially in the cloud, cloud providers often lock down which combinations of storage and compute resources can be chosen, leading to massive overprovisioning on either the storage side or compute side. Anyhow, this typically leads to increased cloud bills.
Disaggregated
Disaggregated storage solutions store the actual data separate from your workloads. Hence independent scaling of storage resources and compute resources is the main reason for disaggregated setups.
A disaggregated setup connects through a network protocol. Depending on the type of disaggregated storage this can be iSCSI or NVMe over Fabrics for block devices, SMB, NFS, or others for file storage, and typically a S3-compatible protocol for object storage.
Disaggregated setups come at a higher complexity as you need to manage two separate clusters. If your storage solution can run in Kubernetes, such as simplyblock, you can select a separate node pool inside the Kubernetes cluster to run the storage engine. This way you have a unified deployment and management model while benefitting from the independent scalability of storage and compute.
Hybrid Setup (Simplyblock)
Simplyblock provides a unique way of creating a hybrid setup of hyper-converged and disaggregated, enabling the best of both worlds. In addition, simplyblock can also run fully hyper-converged or disaggregated.
Wth simplyblock, ultra-latency-sensitive workloads, such as databases, can utilize the co-located NVMe storage (inside the Kubernetes worker) as a tier-0 storage. That way, data is available locally for fastest access but parity or recovery information is still spread around the storage cluster. Additionally, simplyblock can “spill over” to disaggregated nodes (which are part of the same storage cluster) in case the local disk runs full. This solves potential issues in situations where a sudden surge in storage volume occurs and workloads cannot be moved quickly enough.
Also, if a worker node dies, simplyblock seamlessly provides the volume to another worker, while the data is moved to the local NVMe disk of the new worker node.
Data Protection and Availability: Beyond Basic Backups
Data protection in your Kubernetes environments requires a sophisticated approach that goes beyond simple backup and restore capabilities. Enterprises typically need comprehensive strategies to ensure both data availability and disaster recovery capabilities.
High availability begins with how your storage solution handles data replication. Traditional approaches often rely on simple copying of data across nodes (replication), while modern solutions employ more sophisticated techniques. Erasure coding, for instance, with simplyblock, provides data protection with significantly lower storage overhead than full replication. This approach breaks data into fragments, encodes it with redundant data pieces, and stores it across different locations. When implemented properly, this technique can provide the same level of protection as multiple copies while using significantly less storage.
Recovery capabilities have also evolved considerably. Point-in-time recovery has become increasingly important as organizations face threats like ransomware and accidental data deletion. Modern storage solutions achieve this through continuous data protection, maintaining a detailed log of all changes that allows recovery to any previous point in time. This capability proves invaluable when you need to recover from logical corruption that might not be immediately detected.
📝 Editor’s Note: Simplyblock’s approach to data protection combines erasure coding with continuous data protection via streaming to S3-compatible storage. This provides enterprise-grade reliability with minimal storage overhead and enables recovery points measured in seconds rather than hours.
Performance Considerations
Performance in NVMe and Kubernetes storage isn’t simply about raw speed – it’s about matching your application’s specific needs with the right performance characteristics. Latency-sensitive applications, such as financial trading platforms or real-time analytics systems, require consistently low latency measured in microseconds or even nanoseconds. These applications benefit from storage solutions that leverage NVMe technology and sophisticated caching mechanisms.
High-throughput workloads present a different challenge. When processing large datasets for AI/ML training or handling continuous streams of log data, the ability to maintain consistent high throughput becomes more important than individual operation latency. Storage solutions must provide efficient data streaming capabilities while managing resources effectively to prevent bottlenecks — especially in scale-out AI storage environments where performance must scale alongside data growth.
📝 Editor’s Note: Simplyblock’s NVMe-first data platform provides the fastest option for latency-sensitive applications, as well as high-throughput requirements. Due to its unique capability of creating hybrid storage clusters with hyper-converged and disaggregated nodes, the latency, capacity, and throughput requirements can be catered specifically to every workload.
Security: A Multi-layered Approach
Security in Kubernetes storage extends far beyond basic encryption. Modern organizations require an extensive security framework that protects data throughout its lifecycle. Furthermore, many companies need to ensure compliance with various regulatory requirements.
Encryption forms the foundation of data security, but its implementation requires careful consideration. At-rest encryption protects data stored on physical media, while in-transit encryption secures data as it moves between components. However, key management proves equally important – organizations need robust systems for managing encryption keys, including secure key rotation and access controls.
Multi-tenancy presents unique security challenges in Kubernetes environments. Storage solutions must provide complete isolation between different tenants while still allowing efficient resource sharing. This requires sophisticated access control mechanisms and careful attention to network isolation. Role-Based Access Control (RBAC) provides the granular permissions needed to ensure users can access only the resources they need.
Cost Optimization: Beyond Price Per Gigabyte
Understanding storage costs in Kubernetes requires looking beyond simple capacity pricing. The true cost of storage includes several components that organizations often overlook initially.Storage efficiency technologies can dramatically impact overall costs. Take thin provisioning, for example. Traditional storage allocation often leads to significant waste, with organizations provisioning storage for peak usage that rarely materializes. Modern thin provisioning allows organizations to allocate storage on demand, significantly reducing waste and associated costs.
Automated tiering represents another powerful cost optimization strategy. Not all data requires the same level of performance, and storing rarely accessed data on high-performance storage wastes resources. By automatically moving data between performance tiers based on access patterns, organizations can optimize both cost and performance.
Consider this real-world example: A typical enterprise application might generate 1TB of data per month, but only 20% of that data remains actively accessed after 30 days. By implementing automated tiering, this organization could keep frequently accessed data on high-performance storage while moving older data to more cost-effective tiers, potentially reducing storage costs by 50-70%.
📝 Editor’s Note: For AWS environments, simplyblock provides a tool to understand your current usage of Amazon EBS inside your Kubernetes cluster.
Management and Operations
Implementing a storage solution represents just the beginning of your journey. Continuous monitoring, observability, and optimization become crucial for maintaining optimal performance and identifying potential issues before they impact production workloads.
Monitoring and Observability
Modern storage solutions provide rich telemetry data that enables comprehensive monitoring. However, the key lies in understanding which metrics matter for your specific use case. While IOPS and latency measurements provide important baseline information, administrators should also track metrics like cache hit rates, queue depths, and storage tier distribution. These metrics offer deeper insights into system behavior and can help identify optimization opportunities.
Integration with popular monitoring platforms like Prometheus and Grafana has become standard practice. These tools enable teams to create comprehensive dashboards that combine storage metrics with application and infrastructure data, providing a complete view of system performance. More importantly, they enable the creation of meaningful alerts based on trends rather than simple thresholds.
Ongoing Operations, Optimization, and Capacity Planning
Storage operation and optimization represent an ongoing process rather than a one-time effort. As applications evolve and workload patterns change, storage configurations often require adjustment to maintain optimal performance and cost-efficiency.
Capacity planning deserves particular attention in Kubernetes environments, where storage needs can grow rapidly and sometimes unpredictably. Modern storage solutions help address this challenge through predictive analytics and automation. By analyzing usage trends and growth patterns, these systems can predict future capacity requirements and automatically adjust resources as needed.
Furthermore, you should ensure that your storage solution provides an API to integrate into your extended deployment automation, such as Terraform scripts, autoscalers, or similar. If it runs in Kubernetes, especially when hyper-converged, and runs out of storage capacity.
Implementation: From Theory to Practice
Successfully implementing a new storage solution requires careful planning and execution. You begin the process with thorough evaluation and testing, move through careful implementation, and continue with ongoing optimization.
Performance testing deserves particular attention during the evaluation phase. Simple benchmark tools often fail to capture real-world performance characteristics. Instead, organizations should develop test scenarios that mirror their actual workloads. This might include running multiple workload types simultaneously, simulating peak usage patterns, and testing failure scenarios.
Furthermore, migration planning requires careful consideration of both technical and operational factors. Organizations must decide between different migration strategies. Valid options are lift-and-shift or gradual migration. Select based on your specific circumstances. Each approach has advantages and risks, which must be carefully weighed against business requirements.
Future-Proofing Your Storage Strategy
Technology evolves rapidly, and today’s storage decisions impact tomorrow’s possibilities. Organizations need to consider how their chosen storage solution will adapt to emerging technologies and changing requirements.
That is why simplyblock is built from the ground up to support modern technology standards such as NVMe over Fabrics and fully settles on an NVMe-first approach. If legacy applications need to be attached, older protocols such as iSCSI are available enabling organizations to slowly migrate as practical.
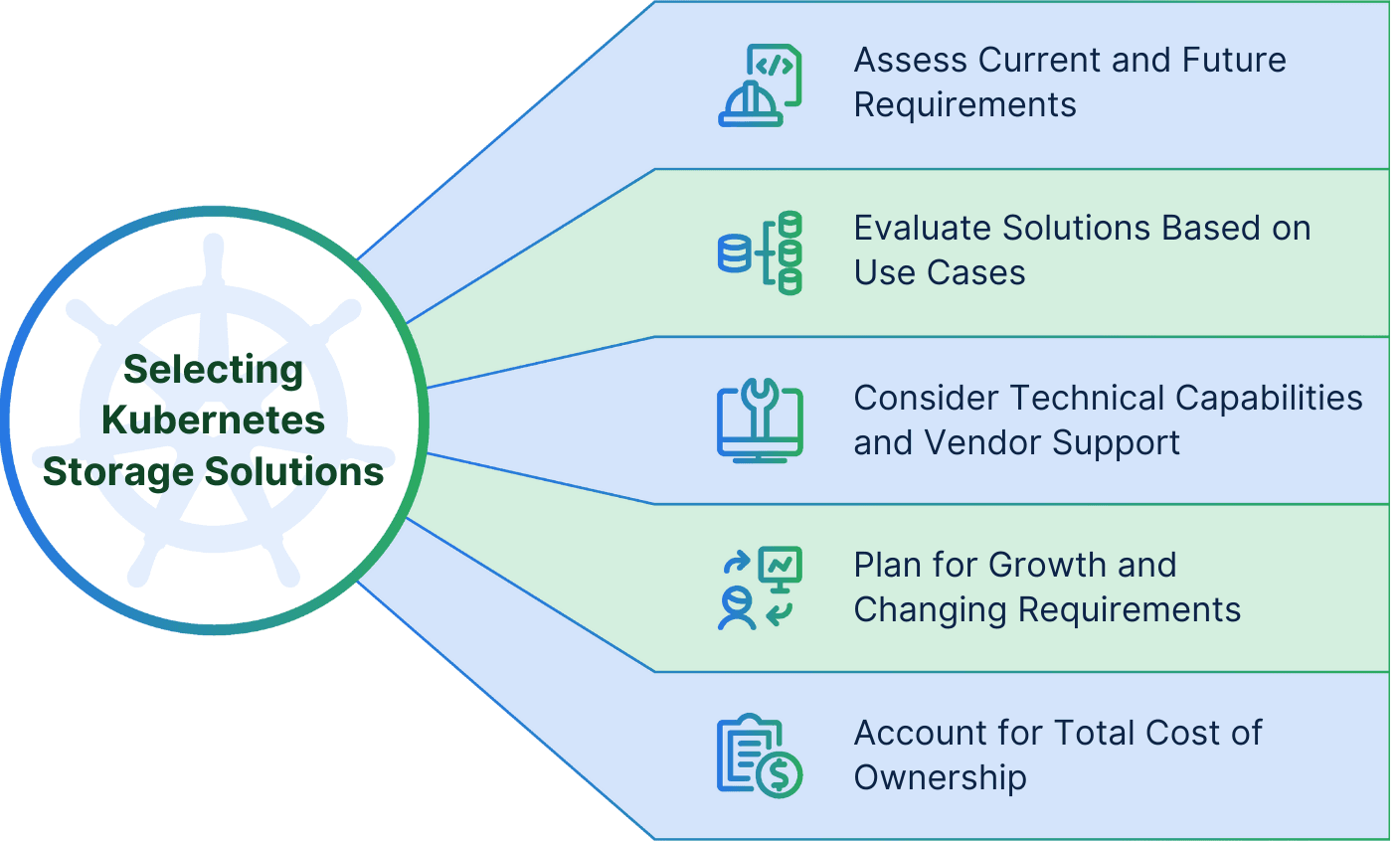
Making an Informed Decision
Selecting the right Kubernetes storage solution requires careful consideration of multiple factors, from technical requirements to operational considerations. Organizations should:
- Thoroughly assess current and future requirements
- Evaluate solutions based on their specific use cases
- Consider both technical capabilities and vendor support
- Plan for growth and changing requirements
- Account for total cost of ownership
The right storage solution enables rather than constrains, providing the foundation for innovation while maintaining reliability and performance. Take time to evaluate options thoroughly, test extensively, and plan implementation carefully. Remember that storage forms a critical part of your infrastructure – choosing wisely pays dividends in the long term.
As Kubernetes environments continue to evolve and grow more complex, having a robust, scalable storage solution becomes increasingly important. The investment made in selecting and implementing the right storage solution will help ensure your organization’s success in the cloud-native landscape.
Simplyblock provides the best contender for scalable and low-latency Kubernetes storage. With its NVMe-first architecture and hybrid setup, simplyblock enables a single storage solution for all kinds of workloads. Get started right away.
Questions and Answers
Kubernetes storage refers to how persistent data is managed in containerized environments. It enables stateful workloads to survive pod restarts and rescheduling. Storage can be local or network-attached, provisioned dynamically, and integrated via the Container Storage Interface (CSI).
Selecting the right Kubernetes storage depends on your workload’s performance, scalability, and availability needs. Look for CSI-compliant, cloud-native options like simplyblock that offer NVMe-over-TCP, replication, and Kubernetes-native encryption.
Performance issues often stem from slow IOPS, high latency, or lack of scalability. Choosing modern storage backends with NVMe and network optimization can resolve these. Learn more about the impact of IOPS and throughput in containerized environments.
Yes, NVMe storage is significantly faster than traditional HDD or SATA SSDs. It offers low latency and high throughput, making it ideal for high-performance Kubernetes applications like databases or analytics platforms.
A CSI driver allows Kubernetes to interact with different storage systems using a standardized interface. This abstraction lets you dynamically provision and manage volumes across clusters. simplyblock offers a CSI-compatible driver for seamless Kubernetes storage integration.


