
Modern cloud applications demand more from their storage than ever before – ultra-low latency, predictable performance, and bulletproof reliability. Simplyblock’s software-defined storage cluster technology, built upon its distributed data placement algorithm, reimagines how we utilize NVMe devices in public cloud environments.
This article deep dives into how we’ve improved upon traditional distributed data placement algorithms to create a high-performance I/O processing environment that meets modern enterprise storage requirements.
Design Of Simplyblock’s Storage Cluster
Simplyblock storage cluster technology is designed to utilize NVMe storage devices in public cloud environments for use cases that require predictable and ultra-low access latency (sub-millisecond) and the highest performance density (high IOPS per GiB).
To combine high performance with a high degree of data durability, high availability, and fault tolerance, as well as zero downtime scalability, the known distributed data placement algorithms had to be improved, re-combined, and implemented into a high-performance IO processing environment.
Our innovative approach combines:
- Predictable, ultra-low latency performance (<1ms)
- Maximum IOPS density optimization
- Enterprise-grade durability and availability
- Zero-downtime scalability
- Advanced failure domain management
Modern Storage Requirements
Use cases such as high-load databases, time-series databases with high-velocity data, Artificial Intelligence (AI), Machine Learning (ML), and many others require fast and predictable storage solutions.
Anyhow, performance isn’t everything. The fastest storage is writing to /dev/null, but only if you don’t need the data durability. That said, the main goals for a modern storage solution are:
- High Performance Density, meaning a high amount of IOPS per Gigabyte (at an affordable price).
- Predictable, low Latency, especially for use cases that require consistent response times.
- High degree of Data Durability, to distribute the data across failure domains, enabling it to survive multiple failure scenarios.
- High Availability and Fault Tolerance, for the data to remain accessible in case of node outage. Clusters are automatically re-balanced in the case of element failures.
- Zero Downtime Scalability, meaning that clusters can grow in real-time and online and are automatically re-balanced.
Distributed Data Placement
Data placement in storage clusters commonly uses pseudo-randomization. Additionally, features such as weighted distribution of storage across the cluster (based on the capacity and performance of available data buckets) are introduced to handle failure domains and cluster rebalancing – for scaling, downsizing, or removal of failed elements – at minimal cost. A prominent example of such an algorithm is CRUSH (Controlled, Scalable, Decentralized Placement of Replicated Data), which is used in Ceph, an open-source software-defined storage platform designed to provide object storage, block storage, and file storage in a unified system.
Simplyblock uses a different algorithm to achieve the following characteristics for its distributed data placement feature:
- High storage efficiency (raw to effective storage ratio) with minimal performance overhead. Instead of using three data replicas, which is the standard mechanism to protect data from storage device failure in software-defined storage clusters, simplyblock uses error coding algorithms with a raw-to-effective ratio of about 1.33 (instead of 3).
- Very low access latency below 100 microseconds for read and write. Possible write amplification below 2.
- Ultra-high IOPS density with more than 200.000 IOPS per CPU core.
- Performant re-distribution of storage in the cluster in the case of cluster scaling and removal of failed storage devices. Simplyblock’s algorithm will only re-distribute the amount of data that is close to the theoretical minimum to rebalance the cluster.
- Support for volume high-availability based on the NVMe industry standard. Support for simple failure domains as they are available in cloud environments (device, node, rack, availability zone).
- Performance efficiency aims to address the typical performance bottlenecks in cloud environments.
Implementing a storage solution to keep up with current trends required us to think out of the box. The technical design consists of several elements.
Low-level I/O Processing Pipeline
On the lower level, simplyblock uses a fixed-size page mapping algorithm implemented in a virtual block device (a virtual block device implements a filter or transformation step in the IO processing pipeline).
For that purpose, IO is organized into “pages” ( 2^m blocks, with m in the range of 8 to 12). Cross-page IO has to be split before processing. This is done on the mid-level processing pipeline. We’ll get to that in a second.
This algorithm can place data received via IO-write requests from multiple virtual block devices on a single physical block device. Each virtual block device has its own logical block address space though. The algorithm is designed to read, write, and unmap (deallocate) data with minimal write amplification for metadata updates (about 2%) and minimal increase in latency (on average in the sub-microseconds range). Furthermore, it is optimized for sudden power cuts (crash-consistent) by storing all metadata inline of the storage blocks on the underlying device.
Like all block device IO requests, each request contains an LBA (logical block address) and a length (in blocks). The 64-bit LBA is internally organized into a 24-bit VUID (a cluster-wide unique identifier of the logical volume) and a 39-bit virtual LBA. The starting LBA of the page on the physical device is identified by the key (VUID, LPA), where LPA is the logical page address (LBA / (2^m)), and the address offset within the page is determined by (LBA modulo 2^m).
The IO processing services of this virtual device work entirely asynchronously on CPU-pinned threads with entirely private data (no synchronization mechanisms between IO threads required).
They are placed on top of an entirely asynchronous NVMe driver, which receives IO and submits responses via IO-queue pairs sitting at the bottom of the IO processing stack.
Mid-level IO Processing Pipeline
On top of the low-level mapping device, a virtual block device, which implements distributed data placement, has access to the entire cluster topology. This topology is maintained by a centralized multi-tenant control plane, which knows about the state of each node and device in the attached clusters and manages changes to cluster topology (adding or removing devices and nodes).
It uses multiple mechanisms to determine the calculated and factual location of each data page and then issues asynchronous IO to this mapping device in the cluster locally (NVMe) or remotely using NVMe over Fabrics (NVMe-oF):
- All IO is received and forwarded on private IO threads, with no inter-thread communication, and entirely asynchronously, both inbound and outbound.
- First, IO is split at page boundaries so that single requests can be processed within a single page.
- Data is then striped into n chunks, and (double) parity is calculated from the chunks. Double parity is calculated using the RDP algorithm. The data is, therefore, organized in 2-dimensional arrays. n equals 1, 2, 4, or 8. This way, 4 KiB blocks can be mapped into 512-byte device blocks, and expensive partial stripe writes can be avoided.
- To determine a primary target for each combination of (VUID, page, chunk-index), a flat list of devices is fed into the “list bucket” algorithm (see …) with (VUID, page, chunk-index) being the key.
- Each of the data and parity chunks in a stripe have to be placed on a different device. In addition, more failure domains, such as nodes and racks, can be considered for placement anti-affinity rules. In case of a collision, the algorithm repeats recursively with an adjusted chunk-index (chunk-index + i x p, where p is the next prime number larger than the maximum chunk index and i is the iteration).
- In case a selected device is (currently) not available, the algorithm repeats recursively to find an alternative and also stores the temporary placement data for each chunk in the IO. This temporary placement data is now also journaled as metadata. Metadata journaling is an important and complex part of the algorithm. It is described separately below.
- On read, the process is reversed: the chunks to read from a determined placement location are determined by the same algorithm.
- In case of single or dual device failure at read, the missing data will be reconstructed on the fly from parity chunks.
- The algorithm pushes any information on IO errors straight to the control plane, and the control plane may update the cluster map (status of nodes and devices) and push the updated cluster map back to all nodes and virtual devices.
Top-level IO Processing Pipeline
On top of the stack of virtual block devices, simplyblock includes multiple optional virtual block devices, including a snapshot device – the device can take instant snapshots of volumes, supports snapshot chains, and instant (copy-on-write) cloning of volumes. Additionally, there is a virtual block device layer, which supports synchronous and asynchronous replication of block storage volumes across availability zones.
The highest virtual block device in the stack is then published to the fabric as a separate NVMe-oF volume with its own unique NVMe identifier (NQN) via the control plane.
High-Availability Support
The algorithm supports highly available volumes based on NVMe multipathing and ANA (asynchronous namespace access). This means that a transparent fail-over of IO for a single volume in case of a node outage is realized without having to add any additional software to clients.
Due to the features of the high-, mid-, and low-level IO pipeline, this is easy to realize: identical stacks of virtual block devices with an identical VUID are created on multiple nodes and published to the fabric using “asynchronous namespace access” (which prefers one volume over others and essentially implements an active/passive/passive mechanism).
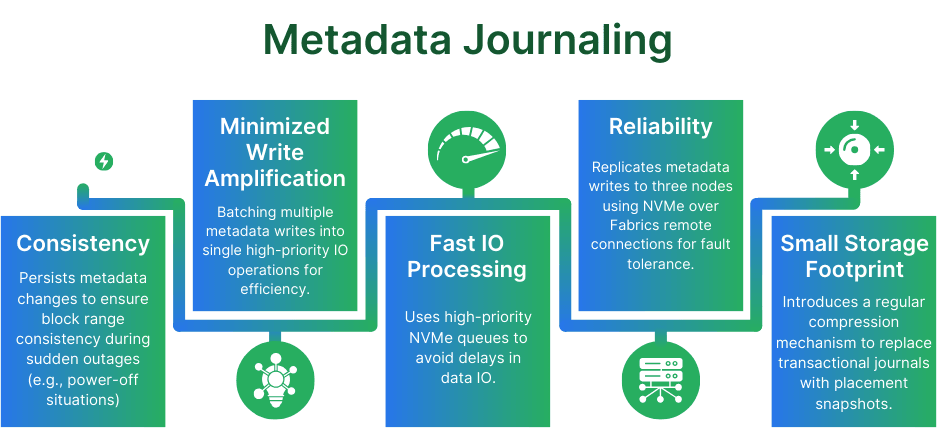
Metadata Journaling
Metadata Journaling persists in non-primary placement locations to locate data in the cluster. It has the following important features:
- It has to persist every change in location for the block range addressed in an IO request to be consistent in “sudden power-off” situations (node outages)
- It has to minimize write amplification – this is achieved by smartly “batching” multiple metadata write requests into single IO operations in the form of “high-priority” IO
- It has to be fast – not delaying data IO – this is achieved by high-priority NVMe queues
- It has to be reliable – this is achieved by replicating metadata writes to three nodes using NVMe over Fabrics remote connections
- Its storage footprint has to be small and remain constant over time; it cannot grow forever with new IO – this is achieved by introducing a regular compression mechanism, which replaces the transactional journal with a “snapshot” of placement metadata at a certain moment
Data Migrations
Data Migrations run as background processes, which take care of the movement of data in cases of failed devices (re-rebuild and re-distribution of data in the cluster), cluster scaling (to reduce the load on utilized elements and rebalance the cluster), and temporary element outage (to migrate data back to its primary locations). Running data migrations keeps a cluster in a state of transition and has to be coordinated to not conflict with any ongoing IO.
Conclusion
Building an architecture for a fast, scalable, fault-tolerant distributed storage solution isn’t easy. To be fair, I don’t think anyone expected that. Distributed systems are always complicated, and a lot of brain power goes into their design.
Simplyblock separates itself by rethinking the data placement in distributed storage environments. Part of it is the fundamentally different way of using erasure coding for parity information. We don’t just use them on a single node, between the local drives, simplyblock uses erasure coding throughout the cluster, distributing parity information from each disk on another disk on another node, hence increasing the fault tolerance.
To test simplyblock, get started right away. If you want to learn more about the features simplyblock offers you, see our feature overview.
Questions and Answers
A distributed data placement algorithm determines how data is efficiently and reliably distributed across multiple storage nodes in a cluster. It balances performance, redundancy, and fault tolerance—core to modern distributed storage systems.
Simplyblock uses a custom-built algorithm based on consistent hashing and topology-aware replication. This ensures optimal data placement with minimal rebalancing and high availability across zones, enabling fast failover and efficient recovery in large-scale environments.
Consistent hashing reduces data movement when nodes are added or removed, making it ideal for dynamic environments. Simplyblock’s implementation enhances this with rack-awareness and performance-aware placement for improved resilience and efficiency.
Topology-aware replication ensures that data replicas are stored across failure domains like racks or zones. This increases fault tolerance and availability, which is crucial for workloads running on Kubernetes or in hybrid cloud setups.
The algorithm considers node capacity, network proximity, and device performance to ensure balanced placement. Combined with NVMe over TCP and data-at-rest encryption, simplyblock delivers high-throughput, low-latency storage with strong data protection.


