NVMe Storage for Database Optimization: Lessons from Tech Giants
Oct 17th, 2024 | 12 min read

Database Scalability Challenges in the Age of NVMe
In 2024, data-driven organizations increasingly recognize the crucial importance of adopting NVMe storage solutions to stay competitive. With NVMe adoption still below 30%, there’s significant room for growth as companies seek to optimize their database performance and storage efficiency. We’ve looked at how major tech companies have tackled database optimization and scalability challenges, often turning to self-hosted database solutions and NVMe storage.
While it’s interesting to see what Netflix or Pinterest engineers are investing their efforts into, it is also essential to ask yourself how your organization is adopting new technologies. As companies grow and their data needs expand, traditional database setups often struggle to keep up. Let’s look at some examples of how some of the major tech players have addressed these challenges.
Pinterest’s Journey to Horizontal Database Scalability with TiDB
Pinterest, which handles billions of pins and user interactions, faced significant challenges with its HBase setup as it scaled. As their business grew, HBase struggled to keep up with evolving needs, prompting a search for a more scalable database solution. They eventually decided to go with TiDB as it provided the best performance under load.
Selection Process:
- Evaluated multiple options, including RocksDB, ShardDB, Vitess, VoltDB, Phoenix, Spanner, CosmosDB, Aurora, TiDB, YugabyteDB, and DB-X.
- Narrowed down to TiDB, YugabyteDB, and DB-X for final testing.
Evaluation:
- Conducted shadow traffic testing with production workloads.
- TiDB performed well after tuning, providing sustained performance under load.
TiDB Adoption:
- Deployed 20+ TiDB clusters in production.
- Stores over 200+ TB of data across 400+ nodes.
- Primarily uses TiDB 2.1 in production, with plans to migrate to 3.0.
Key Benefits:
- Improved query performance, with 2-10x improvements in p99 latency.
- More predictable performance with fewer spikes.
- Reduced infrastructure costs by about 50%.
- Enabled new product use cases due to improved database performance.
Challenges and Learnings:
- Encountered issues like TiCDC throughput limitations and slow data movement during backups.
- Worked closely with PingCAP to address these issues and improve the product.
Future Plans:
- Exploring multi-region setups.
- Considering removing Envoy as a proxy to the SQL layer for better connection control.
- Exploring migrating to Graviton instance types for a better price-performance ratio and EBS for faster data movement (and, in turn, shorter MTTR on node failures).
Uber’s Approach to Scaling Datastores with NVMe
Uber, facing exponential growth in active users and ride volumes, needed a robust solution for their datastore “Docstore” challenges.
Hosting Environment and Limitations:
- Initially on AWS, later migrated to hybrid cloud and on-premises infrastructure
- Uber’s massive scale and need for customization exceeded the capabilities of managed database services
Uber’s Solution: Schemaless and MySQL with NVMe
- Schemaless: A custom solution built on top of MySQL
- Sharding: Implemented application-level sharding for horizontal scalability
- Replication: Used MySQL replication for high availability
- NVMe storage: Leveraged NVMe disks for improved I/O performance
Results:
- Able to handle over 100 billion queries per day
- Significantly reduced latency for read and write operations
- Improved operational simplicity compared to Cassandra
Discord’s Storage Evolution and NVMe Adoption
Discord, facing rapid growth in user base and message volume, needed a scalable and performant storage solution.
Hosting Environment and Limitations:
- Google Cloud Platform (GCP)
- Discord’s specific performance requirements and need for customization led them to self-manage their database infrastructure
Discord’s storage evolution:
- MongoDB: Initially used for its flexibility, but faced scalability issues
- Cassandra: Adopted for better scalability but encountered performance and maintenance challenges
- ScyllaDB: Finally settled on ScyllaDB for its performance and compatibility with Cassandra
Discord also created a solution, “superdisk” with a RAID0 on top of the Local SSDs, and a RAID1 between the Persistent Disk and RAID0 array. They could configure the database with a disk drive that would offer low-latency reads while still allowing us to benefit from the best properties of Persistent Disks. One can think of it as a “simplyblock v0.1”.
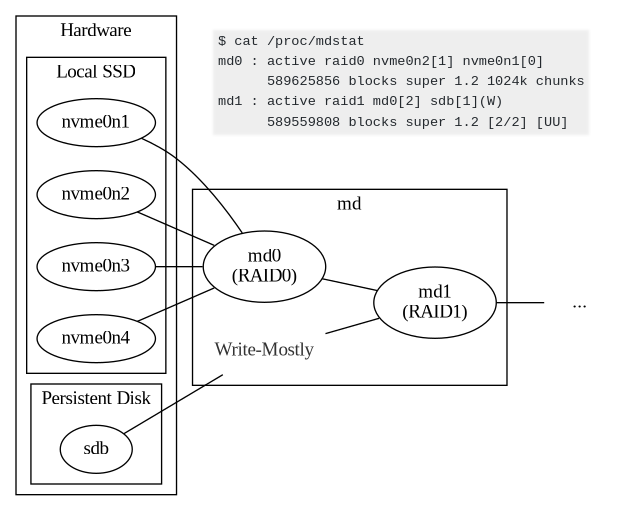
Key improvements with ScyllaDB:
- Reduced P99 latencies from 40-125ms to 15ms for read operations
- Improved write performance, with P99 latencies dropping from 5-70ms to a consistent 5ms
- Better resource utilization, allowing Discord to reduce their cluster size from 177 Cassandra nodes to just 72 ScyllaDB nodes
Summary of Case Studies
In the table below, we can see a summary of the key initiatives taken by tech giants and their respective outcomes. What is notable, all of the companies were self-hosting their databases (on Kubernetes or on bare-metal servers) and have leveraged local SSD (NVMe) for improved read/write performance and lower latency. However, at the same time, they all had to work around data protection and scalability of the local disk. Discord, for example, uses RAID to mirror the disk, which causes significant storage overhead. Such an approach doesn’t also offer a logical management layer (i.e. “storage/disk virtualization”). In the next paragraphs, let’s explore how simplyblock adds even more performance, scalability, and resource efficiency to such setups.
| Company | Database | Hosting environment | Key Initiative |
|---|---|---|---|
| TiDB | AWS EC2 & Kubernetes, local NVMe disk | Improved performance & scalability | |
| Uber | MySQL | Bare-metal, NVMe storage | Reduced read/write latency, improved scalability |
| Discord | ScyllaDB | Google Cloud, local NVMe disk with RAID mirroring | Reduced latency, improved performance and resource utilization |
The Role of Intelligent Storage Optimization in NVMe-Based Systems
While these case studies demonstrate the power of NVMe and optimized database solutions, there’s still room for improvement. This is where intelligent storage optimization solutions like simplyblock are spearheading market changes.
Simplyblock vs. Local NVMe SSD: Enhancing Database Scalability
While local NVMe disks offer impressive performance, simplyblock provides several critical advantages for database scalability. Simplyblock builds a persistent layer out of local NVMe disks, which means that is not just a cache and it’s not just ephemeral storage. Let’s explore the benefits of simplyblock over local NVMe disk:
- Scalability: Unlike local NVMe storage, simplyblock offers dynamic scalability, allowing storage to grow or shrink as needed. Simplyblock can scale performance and capacity beyond the local node’s disk size, significantly improving tail latency.
- Reliability: Data on local NVMe is lost if an instance is stopped or terminated. Simplyblock provides advanced data protection that survives instance outages.
- High Availability: Local NVMe loses data availability during the node outage. Simplyblock ensures storage remains fully available even if a compute instance fails.
- Data Protection Efficiency: Simplyblock uses erasure coding (parity information) instead of triple replication, reducing network load and improving effective-to-raw storage ratios by about 150% (for a given amount of NVMe disk, there is 150% more usable storage with simplyblock).
- Predictable Performance: As IOPS demand increases, local NVMe access latency rises, often causing a significant increase in tail latencies (p99 latency). Simplyblock maintains constant access latencies at scale, improving both median and p99 access latency. Simplyblock also allows for much faster write at high IOPS as it’s not using NVMe layer as write-through cache, hence its performance isn’t dependent on a backing persistent storage layer (e.g. S3)
- Maintainability: Upgrading compute instances impacts local NVMe storage. With simplyblock, compute instances can be maintained without affecting storage.
- Data Services: Simplyblock provides advanced data services like snapshots, cloning, resizing, and compression without significant overhead on CPU performance or access latency.
- Intelligent Tiering: Simplyblock automatically moves infrequently accessed data to cheaper S3 storage, a feature unavailable with local NVMe.
- Thin Provisioning: This allows for more efficient use of storage resources, reducing overprovisioning common in cloud environments.
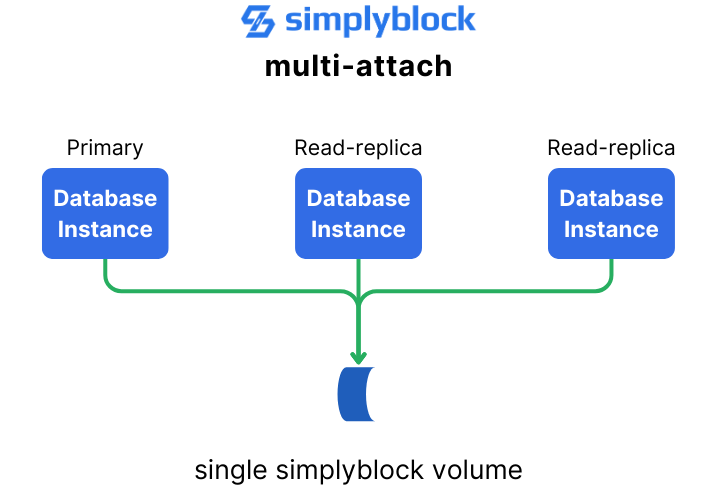
- Multi-attach Capability: Simplyblock enables multiple nodes to access the same volume, which is useful for high-availability setups without data duplication. Additionally, multi-attach can decrease the complexity of volume management and data synchronization.
Technical Deep Dive: Simplyblock’s Architecture
Simplyblock’s architecture is designed to maximize the benefits of NVMe while addressing common cloud storage challenges:
- NVMe-oF (NVMe over Fabrics) Interface: Exposes storage as NVMe volumes, allowing for seamless integration with existing systems while providing the low-latency benefits of NVMe.
- Distributed Data Plane: Uses a statistical placement algorithm to distribute data across nodes, balancing performance and reliability.
- Logical Volume Management: Supports thin provisioning, instant resizing, and copy-on-write clones, providing flexibility for database operations.
- Asynchronous Replication: Utilizes a block-storage-level write-ahead log (WAL) that’s asynchronously replicated to object storage, enabling disaster recovery with near-zero RPO (Recovery Point Objective).
- CSI Driver: Provides seamless integration with Kubernetes, enabling dynamic provisioning and lifecycle management of volumes in NVMe and Kubernetes environments.
Below is a short overview of simplyblock’s high-level architecture in the context of PostgreSQL, MySQL, or Redis instances hosted in Kubernetes. Simplyblock creates a clustered shared pool out of local NVMe storage attached to Kubernetes compute worker nodes (storage is persistent, protected by erasure coding), serving database instances with the performance of local disk but with an option to scale out into other nodes (which can be either other compute nodes or separate, disaggregated, storage nodes). Further, the “colder” data is tiered into cheaper storage pools, such as HDD pools or object storage.
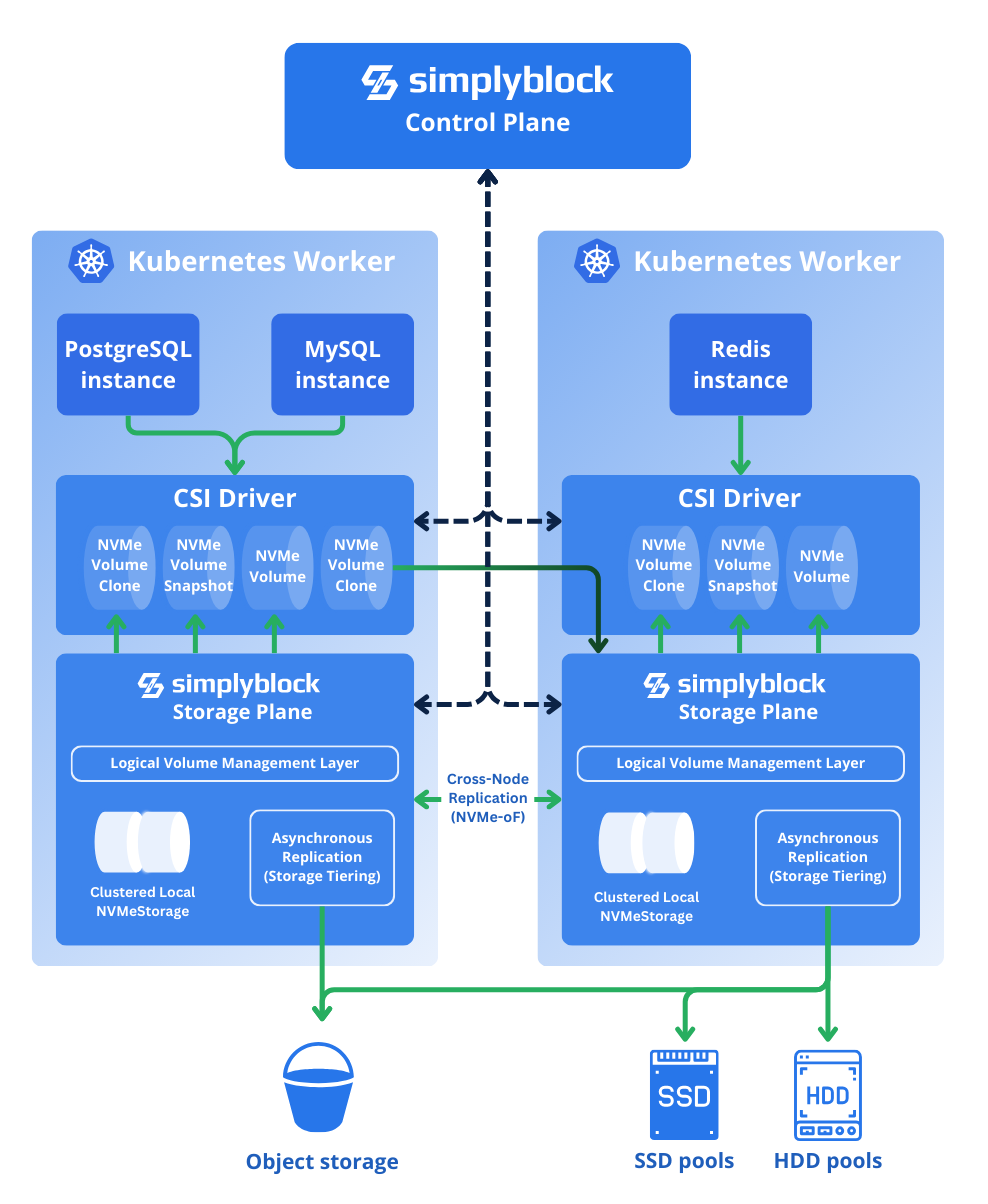
Applying Simplyblock to Real-World Scenarios
Let’s explore how simplyblock could enhance the setups of the companies we’ve discussed:
Pinterest and TiDB with simplyblock
While TiDB solved Pinterest’s scalability issues, and they are exploring Graviton instances and EBS for a better price-performance ratio and faster data movement, simplyblock could potentially offer additional benefits:
- Price/Performance Enhancement: Simplyblock’s storage orchestration could complement Pinterest’s move to Graviton instances, potentially amplifying the price-performance benefits. By intelligently managing storage across different tiers (including EBS and local NVMe), simplyblock could help optimize storage costs while maintaining or even improving performance.
- MTTR Improvement & Faster Data Movements: In line with Pinterest’s goal of faster data movement and reduced Mean Time To Recovery (MTTR), simplyblock’s advanced data management capabilities could further accelerate these processes. Its efficient data protection with erasure coding and multi-attach capabilities helps with smooth failovers or node failures without performance degradation. If a node fails, simplyblock can quickly and autonomously rebuild the data on another node using parity information provided by erasure coding, eliminating downtime.
- Better Scalability through Disaggregation: Simplyblock’s architecture allows for the disaggregation of storage and compute, which aligns well with Pinterest’s exploration of different instance types and storage options. This separation would provide Pinterest with greater flexibility in scaling their storage and compute resources independently, potentially leading to more efficient resource utilization and easier capacity planning.
Uber’s Schemaless
While Uber’s custom Schemaless solution on MySQL with NVMe storage is highly optimized, simplyblock could still offer benefits:
- Unified Storage Interface: Simplyblock could provide a consistent interface across Uber’s diverse storage needs, simplifying operations.
- Intelligent Data Placement: For Uber’s time-series data (like ride information), simplyblock’s tiering could automatically optimize data placement based on age and access patterns.
- Enhanced Disaster Recovery: Simplyblock’s asynchronous replication to S3 could complement Uber’s existing replication strategies, potentially improving RPO.
Discord and ScyllaDB
Discord’s move to ScyllaDB already provided significant performance improvements, but simplyblock could further enhance their setup:
- NVMe Resource Pooling: By pooling NVMe resources across nodes, simplyblock would allow Discord to further reduce their node count while maintaining performance.
- Cost-Efficient Scaling: For Discord’s rapidly growing data needs, simplyblock’s intelligent tiering could help manage costs as data volumes expand.
- Simplified Cloning for Testing: Simplyblock’s instant cloning feature could be valuable for Discord’s development and testing processes.It allows for quick replication of production data without additional storage overhead.
What’s next in the NVMe Storage Landscape?
The case studies from Pinterest, Uber, and Discord highlight the importance of continuous innovation in database and storage technologies. These companies have pushed beyond the limitations of managed services like Amazon RDS to create custom, high-performance solutions often built on NVMe storage.
However, the introduction of intelligent storage optimization solutions like simplyblock represents the next frontier in this evolution. By providing an innovative layer of abstraction over diverse storage types, implementing smart data placement strategies, and offering features like thin provisioning and instant cloning alongside tight integration with Kubernetes, simplyblock spearheads market changes in how companies approach storage optimization.
As data continues to grow exponentially and performance demands increase, the ability to intelligently manage and optimize NVMe storage will become ever more critical. Solutions that can seamlessly integrate with existing infrastructure while providing advanced features for performance, cost optimization, and disaster recovery will be key to helping companies navigate the challenges of the data-driven future.
The trend towards NVMe adoption, coupled with intelligent storage solutions like simplyblock is set to reshape the database infrastructure landscape. Companies that embrace these technologies early will be well-positioned to handle the data challenges of tomorrow, gaining a significant competitive advantage in their respective markets.
Questions and Answers
NVMe (Non-Volatile Memory Express) is a high-speed storage protocol designed for SSDs connected via PCIe. It reduces latency and increases IOPS compared to older protocols like SATA or SAS. Learn more in our NVMe storage glossary.
NVMe accelerates query processing, improves transaction throughput, and reduces read/write latency—making it ideal for high-performance databases like PostgreSQL or MongoDB. When paired with Kubernetes-based workloads, NVMe unlocks significant performance gains.
Databases with high I/O demands, such as PostgreSQL, MySQL, Cassandra, and MongoDB, benefit the most from NVMe storage. These systems experience faster indexing, backups, and analytics processing, especially when deployed with NVMe over TCP.
Companies like Netflix, Meta, and Dropbox adopt NVMe to ensure ultra-low latency, rapid data access, and scalable infrastructure. NVMe helps meet SLAs and performance expectations in massive, distributed database environments across global data centers.
Absolutely. Simplyblock enables NVMe over TCP at scale, combining it with encryption, snapshots, and multi-tenant isolation. It’s an ideal fit for database performance optimization in modern infrastructure.


