![]() Sanskar Gurdasani (Guest Author, CloudRaft)
Sanskar Gurdasani (Guest Author, CloudRaft)
How to Build Scalable and Reliable PostgreSQL Systems on Kubernetes
Nov 25th, 2024 | 13 min read

This is a guest post by Sanskar Gurdasani, DevOps Engineer, from CloudRaft.
Maintaining highly available and resilient PostgreSQL databases is crucial for business continuity in today’s cloud-native landscape. The Cloud Native PostgreSQL Operator provides robust capabilities for managing PostgreSQL clusters in Kubernetes environments, particularly in handling failover scenarios and implementing disaster recovery strategies.
In this blog post, we’ll explore the key features of the Cloud Native PostgreSQL Operator for managing failover and disaster recovery. We’ll discuss how it ensures high availability, implements automatic failover, and facilitates disaster recovery processes. Additionally, we’ll look at best practices for configuring and managing PostgreSQL clusters using this operator in Kubernetes environments.
Why to run Postgres on Kubernetes?
Running PostgreSQL on Kubernetes offers several advantages for modern, cloud-native applications:
- Stateful Workload Readiness: Contrary to old beliefs, Kubernetes is now ready for stateful workloads like databases. A 2021 survey by the Data on Kubernetes Community revealed that 90% of respondents believe Kubernetes is suitable for stateful workloads, with 70% already running databases in production.
- Immutable Application Containers: CloudNativePG leverages immutable application containers, enhancing deployment safety and repeatability. This approach aligns with microservice architecture principles and simplifies updates and patching.
- Cloud-Native Benefits: Running PostgreSQL on Kubernetes embraces cloud-native principles, fostering a DevOps culture, enabling microservice architectures, and providing robust container orchestration.
- Automated Management: Kubernetes operators like CloudNativePG extend Kubernetes controllers to manage complex applications like PostgreSQL, handling deployments, failovers, and other critical operations automatically.
- Declarative Configuration: CloudNativePG allows for declarative configuration of PostgreSQL clusters, simplifying change management and enabling Infrastructure as Code practices.
- Resource Optimization: Kubernetes provides efficient resource management, allowing for better utilization of infrastructure and easier scaling of database workloads.
- High Availability and Disaster Recovery: Kubernetes facilitates the implementation of high availability architectures across availability zones and enables efficient disaster recovery strategies.
- Streamlined Operations with Operators: Using operators like CloudNativePG automates all the tasks mentioned above, significantly reducing operational complexity. These operators act as PostgreSQL experts in code form, handling intricate database management tasks such as failovers, backups, and scaling with minimal human intervention. This not only increases reliability but also frees up DBAs and DevOps teams to focus on higher-value activities, ultimately leading to more robust and efficient database operations in Kubernetes environments.
By leveraging Kubernetes for PostgreSQL deployments, organizations can benefit from increased automation, improved scalability, and enhanced resilience for their database infrastructure, with operators like CloudNativePG further simplifying and optimizing these processes.
List of Postgres Operators
Kubernetes operators represent an innovative approach to managing applications within a Kubernetes environment by encapsulating operational knowledge and best practices. These extensions automate the deployment and maintenance of complex applications, such as databases, ensuring smooth operation in a Kubernetes setup.
The Cloud Native PostgreSQL Operator is a prime example of this concept, specifically designed to manage PostgreSQL clusters on Kubernetes. This operator automates various database management tasks, providing a seamless experience for users. Some key features include direct integration with the Kubernetes API server for high availability without relying on external tools, self-healing capabilities through automated failover and replica recreation, and planned switchover of the primary instance to maintain data integrity during maintenance or upgrades.
Additionally, the operator supports scalable architecture with the ability to manage multiple instances, declarative management of PostgreSQL configuration and roles, and compatibility with Local Persistent Volumes and separate volumes for WAL files. It also offers continuous backup solutions to object stores like AWS S3, Azure Blob Storage, and Google Cloud Storage, ensuring data safety and recoverability. Furthermore, the operator provides full recovery and point-in-time recovery options from existing backups, TLS support with client certificate authentication, rolling updates for PostgreSQL minor versions and operator upgrades, and support for synchronous replicas and HA physical replication slots. It also offers replica clusters for multi-cluster PostgreSQL deployments, connection pooling through PgBouncer, a native customizable Prometheus metrics exporter, and LDAP authentication support.
By leveraging the Cloud Native PostgreSQL Operator, organizations can streamline their database management processes on Kubernetes, reducing manual intervention and ensuring high availability, scalability, and security in their PostgreSQL deployments. This operator showcases how Kubernetes operators can significantly enhance application management within a cloud-native ecosystem.
Here are the most popular PostgreSQL operators:
- CloudNativePG (formerly known as Cloud Native PostgreSQL Operator)
- Crunchy Data Postgres Operator (first released in 2017)
- Zalando Postgres Operator (first released in 2017)
- StackGres (released in 2020)
- Percona Operator for PostgreSQL (released in 2021)
- Kubegres (released in 2021)
- Patroni (for HA PostgreSQL solutions using Python.)
Understanding Failover in PostgreSQL
Primary-Replica Architecture
In a PostgreSQL cluster, the primary-replica (formerly master-slave) architecture consists of:
- Primary Node: Handles all write operations and read operations
- Replica Nodes: Maintain synchronized copies of the primary node’s data
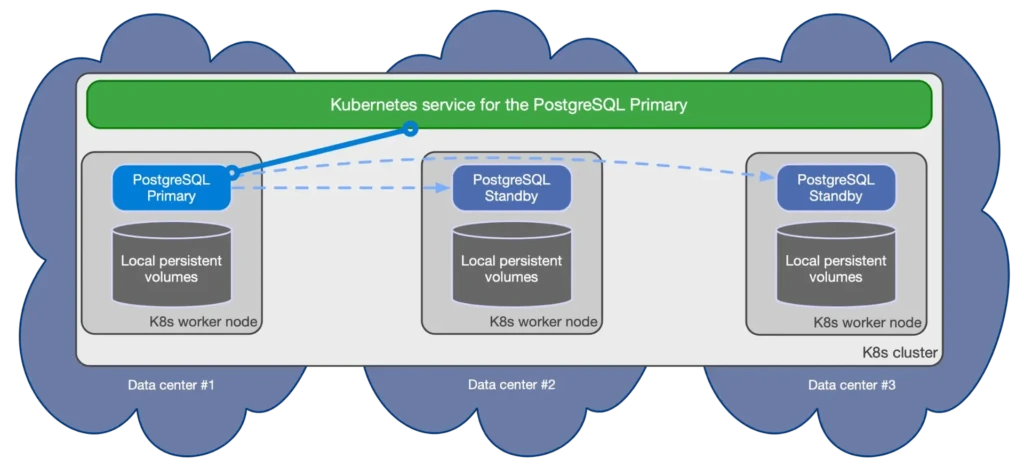
Automatic Failover Process
When the primary node becomes unavailable, the operator initiates the following process:
- Detection: Continuous health monitoring identifies primary node failure
- Election: A replica is selected to become the new primary
- Promotion: The chosen replica is promoted to primary status
- Reconfiguration: Other replicas are reconfigured to follow the new primary
- Service Updates: Kubernetes services are updated to point to the new primary
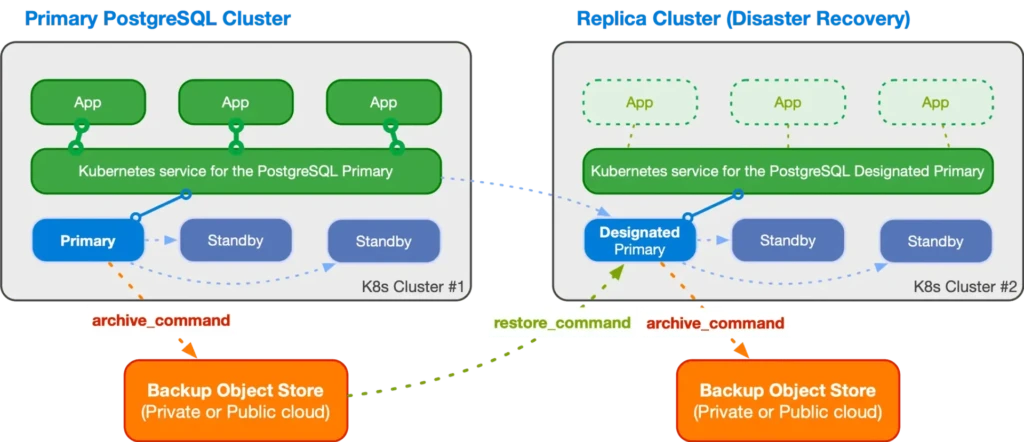
Implementing Disaster Recovery
Backup Strategies
The operator supports multiple backup approaches:
1. Volume Snapshots
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: postgresql-cluster
spec:
instances: 3
backup:
volumeSnapshot:
className: csi-hostpath-snapclass
enabled: true
snapshotOwnerReference: true
2. Barman Integration
spec:
backup:
barmanObjectStore:
destinationPath: 's3://backup-bucket/postgres'
endpointURL: 'https://s3.amazonaws.com'
s3Credentials:
accessKeyId:
name: aws-creds
key: ACCESS\_KEY\_ID
secretAccessKey:
name: aws-creds
key: ACCESS\_SECRET\_KEY
Disaster Recovery Procedures
- Point-in-Time Recovery (PITR)
- Enables recovery to any specific point in time
- Uses WAL (Write-Ahead Logging) archives
- Minimizes data loss
- Cross-Region Recovery
- Maintains backup copies in different geographical regions
- Enables recovery in case of regional failures
Demo
This section provides a step-by-step guide to setting up a CloudNative PostgreSQL cluster, testing failover, and performing disaster recovery.
1. Installation
Method 1: Direct Installation
kubectl apply --server-side -f \
https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/main/releases/cnpg-1.24.0.yaml
Method 2: Helm Installation
helm repo add cnpg https://cloudnative-pg.github.io/charts
helm upgrade --install cnpg \
--namespace cnpg-system \
--create-namespace \
cnpg/cloudnative-pg
Verify the Installation
kubectl get deployment -n cnpg-system cnpg-controller-manager
Install CloudNativePG Plugin
CloudNativePG provides a plugin for kubectl to manage a cluster in Kubernetes. You can install the cnpg plugin using a variety of methods.
Via the installation script
curl -sSfL \
https://github.com/cloudnative-pg/cloudnative-pg/raw/main/hack/install-cnpg-plugin.sh | \
sudo sh -s -- -b /usr/local/bin
If you already have Krew installed, you can simply run:
kubectl krew install cnpg
2. Create S3 Credentials Secret
First, create an S3 bucket and an IAM user with S3 access. Then, create a Kubernetes secret with the IAM credentials:
kubectl create secret generic s3-creds \
--from-literal=ACCESS_KEY_ID=your_access_key_id \
--from-literal=ACCESS_SECRET_KEY=your_secret_access_key
3. Create PostgreSQL Cluster
Create a file named cluster.yaml with the following content:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: example
spec:
backup:
barmanObjectStore:
destinationPath: 's3://your-bucket-name/retail-master-db'
s3Credentials:
accessKeyId:
name: s3-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: s3-creds
key: ACCESS_SECRET_KEY
instances: 2
imageName: ghcr.io/clevyr/cloudnativepg-timescale:16-ts2
postgresql:
shared_preload_libraries:
- timescaledb
bootstrap:
initdb:
postInitTemplateSQL:
- CREATE EXTENSION IF NOT EXISTS timescaledb;
storage:
size: 20Gi
Apply the configuration to create cluster:
kubectl apply -f cluster.yaml
Verify the cluster status:
kubectl cnpg status example
4. Getting Access
Deploying a cluster is one thing, actually accessing it is entirely another. CloudNativePG creates three services for every cluster, named after the cluster name. In our case, these are:
kubectl get service
example-rw: Always points to the Primary nodeexample-ro: Points to only Replica nodes (round-robin)example-r: Points to any node in the cluster (round-robin)
5. Insert Data
Create a PostgreSQL client pod:
kubectl run pgclient --image=postgres:13 --command -- sleep infinity
Connect to the database:
kubectl exec -ti example-1 -- psql app
Create a table and insert data:
CREATE TABLE stocks_real_time (
time TIMESTAMPTZ NOT NULL,
symbol TEXT NOT NULL,
price DOUBLE PRECISION NULL,
day_volume INT NULL
);
SELECT create_hypertable('stocks_real_time', by_range('time'));
CREATE INDEX ix_symbol_time ON stocks_real_time (symbol, time DESC);
GRANT ALL PRIVILEGES ON TABLE stocks_real_time TO app;
INSERT INTO stocks_real_time (time, symbol, price, day_volume)
VALUES
(NOW(), 'AAPL', 150.50, 1000000),
(NOW(), 'GOOGL', 2800.75, 500000),
(NOW(), 'MSFT', 300.25, 750000);
6. Failover Test
Force a backup:
kubectl cnpg backup example
Initiate failover by deleting the primary pod:
kubectl delete pod example-1
Monitor the cluster status:
kubectl cnpg status example
Key observations during failover:
- Initial status: “Switchover in progress”
- After approximately 2 minutes 15 seconds: “Waiting for instances to become active”
- After approximately 3 minutes 30 seconds: Complete failover with new primary
Verify data integrity after failover through service:
Retrieve the database password:
kubectl get secret example-app -o \
jsonpath="{.data.password}" | base64 --decode
Connect to the database using the password:
kubectl exec -it pgclient -- psql -h example-rw -U app
Execute the following SQL queries:
# Confirm the count matches the number of rows inserted earlier. It will show 3
SELECT COUNT(*) FROM stocks_real_time;
#Insert new data to test write capability after failover:
INSERT INTO stocks_real_time (time, symbol, price, day_volume)
VALUES (NOW(), 'NFLX', 500.75, 300000);
SELECT * FROM stocks_real_time ORDER BY time DESC LIMIT 1;
Check read-only service:
kubectl exec -it pgclient -- psql -h example-ro -U app
Once connected, execute:
SELECT COUNT(*) FROM stocks_real_time;
Review logs of both pods:
kubectl logs example-1
kubectl logs example-2
Examine the logs for relevant failover information.
Perform a final cluster status check:
kubectl cnpg status example
Confirm both instances are running and roles are as expected.
7. Backup and Restore Test
First, check the current status of your cluster:
kubectl cnpg status example
Note the current state, number of instances, and any important details.
Promote the example-1 node to Primary:
kubectl cnpg promote example example-1
Monitor the promotion process, which typically takes about 3 minutes to complete.
Check the updated status of your cluster, then create a new backup:
kubectl cnpg backup example –backup-name=example-backup-1
Verify the backup status:
kubectl get backups
NAME AGE CLUSTER METHOD PHASE ERROR
example-backup-1 38m example barmanObjectStore completed
Delete the Original Cluster then prepare for the recovery test:
kubectl delete cluster example
There are two methods available to perform a Cluster Recovery bootstrap from another cluster. For further details, please refer to the documentation. There are two ways to achieve this result in CloudNativePG:
- Using a recovery object store, that is a backup of another cluster created by Barman Cloud and defined via the barmanObjectStore option in the externalClusters section (recommended)
- Using an existing Backup object in the same namespace (this was the only option available before version 1.8.0).
Method 1: Recovery from an Object Store
You can recover from a backup created by Barman Cloud and stored on supported object storage. Once you have defined the external cluster, including all the required configurations in the barmanObjectStore section, you must reference it in the .spec.recovery.source option.
Create a file named example-object-restored.yaml with the following content:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: example-object-restored
spec:
instances: 2
imageName: ghcr.io/clevyr/cloudnativepg-timescale:16-ts2
postgresql:
shared_preload_libraries:
- timescaledb
storage:
size: 1Gi
bootstrap:
recovery:
source: example
externalClusters:
- name: example
barmanObjectStore:
destinationPath: 's3://your-bucket-name'
s3Credentials:
accessKeyId:
name: s3-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: s3-creds
key: ACCESS_SECRET_KEY
Apply the restored cluster configuration:
kubectl apply -f example-object-restored.yaml
Monitor the restored cluster status:
kubectl cnpg status example-object-restored
Retrieve the database password:
kubectl get secret example-object-restored-app \
-o jsonpath="{.data.password}" | base64 --decode
Connect to the restored database:
kubectl exec -it pgclient -- psql -h example-object-restored-rw -U app
Verify the restored data by executing the following SQL queries:
# it should show 4
SELECT COUNT(*) FROM stocks_real_time;
SELECT * FROM stocks_real_time;
The successful execution of these steps to recover from an object store confirms the effectiveness of the backup and restore process.
Delete the example-object-restored Cluster then prepare for the backup object restore test:
kubectl delete cluster example-object-restored
Method 2: Recovery from Backup Object
In case a Backup resource is already available in the namespace in which the cluster should be created, you can specify its name through .spec.bootstrap.recovery.backup.name
Create a file named example-restored.yaml:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: example-restored
spec:
instances: 2
imageName: ghcr.io/clevyr/cloudnativepg-timescale:16-ts2
postgresql:
shared_preload_libraries:
- timescaledb
storage:
size: 1Gi
bootstrap:
recovery:
backup:
name: example-backup-1
Apply the restored cluster configuration:
kubectl apply -f example-restored.yaml
Monitor the restored cluster status:
kubectl cnpg status example-restored
Retrieve the database password:
kubectl get secret example-restored-app \
-o jsonpath="{.data.password}" | base64 --decode
Connect to the restored database:
kubectl exec -it pgclient -- psql -h example-restored-rw -U app
Verify the restored data by executing the following SQL queries:
SELECT COUNT(*) FROM stocks_real_time;
SELECT * FROM stocks_real_time;
The successful execution of these steps confirms the effectiveness of the backup and restore process.
Kubernetes Events and Logs
1. Failover Events
Monitor events using:
# Watch cluster events
kubectl get events --watch | grep postgresql
# Get specific cluster events
kubectl describe cluster example | grep -A 10 Events
- Key events to monitor:
- Primary selection process
- Replica promotion events
- Connection switching events
- Replication status changes
2. Backup Status
Monitor backup progress:
# Check backup status
kubectl get backups
# Get detailed backup info
kubectl describe backup example-backup-1
- Key metrics:
- Backup duration
- Backup size
- Compression ratio
- Success/failure status
3. Recovery Process
Monitor recovery status:
# Watch recovery progress
kubectl cnpg status example-restored
# Check recovery logs
kubectl logs example-restored-1 \-c postgres
- Important recovery indicators:
- WAL replay progress
- Timeline switches
- Recovery target status
Conclusion
The Cloud Native PostgreSQL Operator significantly simplifies the management of PostgreSQL clusters in Kubernetes environments. By following these practices for failover and disaster recovery, organizations can maintain highly available database systems that recover quickly from failures while minimizing data loss. Remember to regularly test your failover and disaster recovery procedures to ensure they work as expected when needed. Continuous monitoring and proactive maintenance are key to maintaining a robust PostgreSQL infrastructure.
Everything fails, all the time. ~ Werner Vogels, CTO, Amazon Web services
Editoral: And if you are looking for looking for a distributed, scalable, reliable, and durable storage for your PostgreSQL cluster in Kubernetes or any other Kubernetes storage need, simplyblock is the solution you’re looking for.
Questions and Answers
Yes, PostgreSQL can run reliably on Kubernetes when paired with a robust storage layer. Using dynamic volumes via a CSI-compatible driver ensures persistent data, high availability, and production-grade resilience.
PostgreSQL benefits most from low-latency, high-IOPS storage like NVMe. A Kubernetes-native storage solution such as Simplyblock with NVMe-over-TCP ensures consistent performance and easy scaling without complex SAN setups.
To ensure data integrity, you need features like snapshots, replication, and encryption at rest. Simplyblock supports these natively and integrates with Kubernetes for seamless database operations.
Self-hosting PostgreSQL on Kubernetes gives you full control, better cost efficiency, and easier customization. When done right—with resilient storage and proper observability—it can match or exceed managed services in performance and flexibility.
NVMe-over-TCP reduces latency and boosts throughput over standard networks. For write-heavy databases like PostgreSQL, this means faster transactions, shorter response times, and improved user experience.


