
Table Of Contents
- Understanding the Basics
- Vertical Scaling (Scale Up) Architectures: The Traditional Approach
- Horizontal Scaling (Scale Out) Architectures: The Distributed Approach
- Kubernetes: A Modern Approach to Scaling
- Why we built Simplyblock on a Scale-Out Architecture
- Building Future-Proof Infrastructure
- The Answer Depends
- Questions and Answers
TLDR: Horizontal scalability (scale out) describes a system that scales by adding more resources through parallel systems, whereas vertical scalability (scale up) increases the amount of resources on a single system.
One of the most important questions to answer when designing an application or infrastructure is the architecture approach to system scalability. Traditionally, systems used the scale-up approach or vertical scalability. Many modern systems use a scale-out approach, especially in the cloud-native ecosystem. Also called horizontal scalability.

Understanding the Basics
Understanding the fundamental concepts is essential when discussing system architectures. Hence, let’s briefly overview the two approaches before exploring them in more depth.
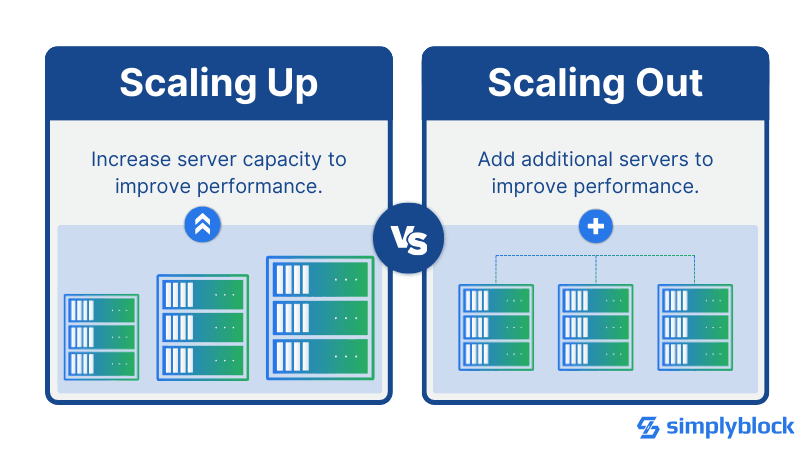
- With Scale Up (Vertical Scalability), you increase resources (typically CPU, memory, and storage) in the existing system to improve performance and capacity.
- With Scale Out (Horizontal Scalability), you add additional nodes or machines to the existing workforce to distribute the workload across multiple systems.
Both architectural approaches have their respective advantages and disadvantages. While scale-up architectures are easier to implement, they are harder to scale at a certain point. On the other hand, scale-out architectures are more complex to implement but scale almost linearly if done right.
Vertical Scaling (Scale Up) Architectures: The Traditional Approach
Vertical scaling, commonly known as scaling up, involves adding more resources to an existing system to increase its power or capacity.
Think of it as upgrading your personal computer. Instead of buying a second computer, you add more RAM or install a faster processor or larger storage device. In enterprise storage systems, this typically means adding more CPU cores, memory, or storage drives to an existing server. Meanwhile, for virtual machines it usually involves increasing the host machine’s assigned resources.
To clarify, let’s use a real-world example from the storage industry. With a ZFS-based SAN (Storage Area Network) system, a scaling up system design is required. Or as Jason Lohrey wrote: «However, ZFS has a significant issue – it can’t scale out. ZFS’s biggest limitation is that it is “scale-up” only.» ZFS, as awesome as it is, is limited to a single machine. That said, increasing the storage capacity always means adding larger or more disks to the existing machine. This approach maintains the simplicity of the original architecture while increasing storage capacity and potentially improving performance.
Strengths of Vertical Scaling
Today, many people see the vertical scalability approach as outdated and superfluous. That is, however, not necessarily true. Vertical scaling shines in several scenarios.
First, implementing a scale-up system is generally more straightforward since it doesn’t require changes to your application architectures or complex data distribution logic. When you scale up a transactional database like PostgreSQL or MySQL, you essentially give it more operational resources while maintaining the same operational model.
Secondly, the management overhead is lower. Tasks such as backups, monitoring, and maintenance are straightforward. This simplicity often translates to lower operational costs despite the potentially higher hardware costs.
Here is a quick overview of all the advantages:
- Simplicity: It’s straightforward to implement since you’re just adding resources to an existing system
- Lower Complexity: Less architectural overhead since you’re working with a single system
- Consistent Performance: Lower latency due to all resources being in one place
- Software Compatibility: Most traditional software is designed to run on a single system
- Lower Initial Costs: Often cheaper for smaller workloads due to simpler licensing and management
Weaknesses and Limitations of Scale-Up Architectures
Like anything in this world, vertical scaling architectures also have drawbacks. The most significant limitation is the so-called physical ceiling. A system is limited by its server chassis’s space capacity or the hardware architecture’s limitation. You can only add as much hardware as those limitations allow. Alternatively, you need to migrate to a bigger base system.
Traditional monolithic applications often face another challenge with vertical scaling: adding more resources doesn’t always translate to linear performance improvements. For example, doubling the CPU cores might yield only a 50% performance increase due to software architecture limitations, especially resource contention.
Here is a quick overview of all the disadvantages:
- Hardware Limits: The physical ceiling limits how much you can scale up based on maximum hardware specifications
- Downtime During Upgrades: Usually requires system shutdown for hardware upgrades
- Cost Efficiency: High-end hardware becomes exponentially more expensive
- Single Point of Failure: No built-in redundancy
- Limited Flexibility: Cannot easily scale back down when demand decreases
When to Scale Up?
After all that, here is when you really want to go with a scale-up architecture:
- You have traditional monolithic applications
- You look for an easier way to optimize for performance, not capacity
- You’re dealing with applications that aren’t designed for distributed computing
- You need a quick solution for immediate performance issues
Horizontal Scaling (Scale Out) Architectures: The Distributed Approach
The fundamentally different approach is the horizontal scaling or scale-out architecture. Instead of increasing the available resources on the existing system, you add more systems to distribute the load across them. This is actually similar to adding additional workers to an assembly line rather than trying to make one worker more efficient.
Consider a distributed storage system like simplyblock or a distributed database like MongoDB. When you scale out these systems, you add more nodes to the cluster, and the workload gets distributed across all nodes. Each node handles a portion of the data and processing, allowing the system to grow almost limitlessly.
Advantages of Horizontal Scaling
Large-scale deployments and highly distributed systems are the forte of scale-out architectures. As a simple example, most modern web applications utilize load balancers. They distribute the traffic across multiple application servers. This allows us to handle millions of concurrent requests and users. Similarly, distributed storage systems like simplyblock scale to petabytes of data by adding additional storage nodes.
Secondly, another significant advantage is improved high availability and fault tolerance. In a properly designed scale-out system, if one node fails, the system continues operating. While it may degrade to a reduced service, it will not experience a complete system failure or outage.
To bring this all to a point:
- Near-Infinite Scalability: Can continue adding nodes as needed
- Better Fault Tolerance: Built-in redundancy through multiple nodes
- Cost Effectiveness: Can use commodity hardware
- Flexible Resource Allocation: Easy to scale up or down based on demand
- High Availability: No single point of failure
The Cost of Distribution: Weakness and Limitations of Horizontal Scalability
The primary challenge when considering scale-out architectures is complexity. Distributed systems must maintain data consistency across system boundaries, handle network communications or latencies, and handle failure recovery. Multiple algorithms have been developed over the years. The most commonly used ones are Raft and Paxos, but that’s a different blog post. Anyhow, this complexity typically requires more sophisticated management tools and distributed systems expertise. Normally also for the team operating the system.
The second challenge is the overhead of system coordination. In a distributed system, nodes must synchronize their operations. If not careful, this can introduce latency and even reduce the performance of certain types of operations. Great distributed systems utilize sophisticated algorithms to prevent these issues from happening.
Here is a quick overview of the disadvantages of horizontal scaling:
- Increased Complexity: More moving parts to manage
- Data Consistency Challenges: Maintaining consistency across nodes can be complex
- Higher Initial Setup Costs: Requires more infrastructure and planning
- Software Requirements: Applications must be designed for distributed computing
- Network Overhead: Communication between nodes adds latency
Kubernetes: A Modern Approach to Scaling
Kubernetes has become the de facto platform for container orchestration. It comes in multiple varieties, in its vanilla form or as the basis for systems like OpenShift or Rancher. Either way, it can be used for both vertical and horizontal scaling capabilities. However, Kubernetes has become a necessity when deploying scale-out services. Let’s look at how different workloads scale in a Kubernetes environment.
Scaling Stateless Workloads
Stateless applications, like web servers or API gateways, are natural candidates for horizontal scaling in Kubernetes. The Horizontal Pod Autoscaler (HPA) provided by Kubernetes automatically adjusts the number of pods based on metrics such as CPU or RAM utilization. Custom metrics as triggers are also possible.
Horizontally scaling stateless applications is easy. As the name suggests, stateless applications do not maintain persistent local or shared state data. Each instance or pod is entirely independent and interchangeable. Each request to the service contains all the required information needed for processing.
That said, automatically scaling up and down (in the meaning of starting new instances or shutting some down) is part of the typical lifecycle and can happen at any point in time.
Scaling Stateful Workloads
Stateful workloads, like databases, require more careful consideration.
A common approach for more traditional databases like PostgreSQL or MySQL is to use a primary-replica architecture. In this design, write operations always go to the primary instance, while read operations can be distributed across all replicas.
On the other hand, MongoDB, which uses a distributed database design, can scale out more naturally by adding more shards to the cluster. Their internal cluster design uses a technique called sharding. Data is assigned to horizontally scaling partitions distributed across the cluster nodes. Shard assignment happens either automatically (based on the data) or by providing a specific shard key, enabling data affinity. Adding a shard to the cluster will increase capacity when additional scale is necessary. Data rebalancing happens automatically.
Why we built Simplyblock on a Scale-Out Architecture
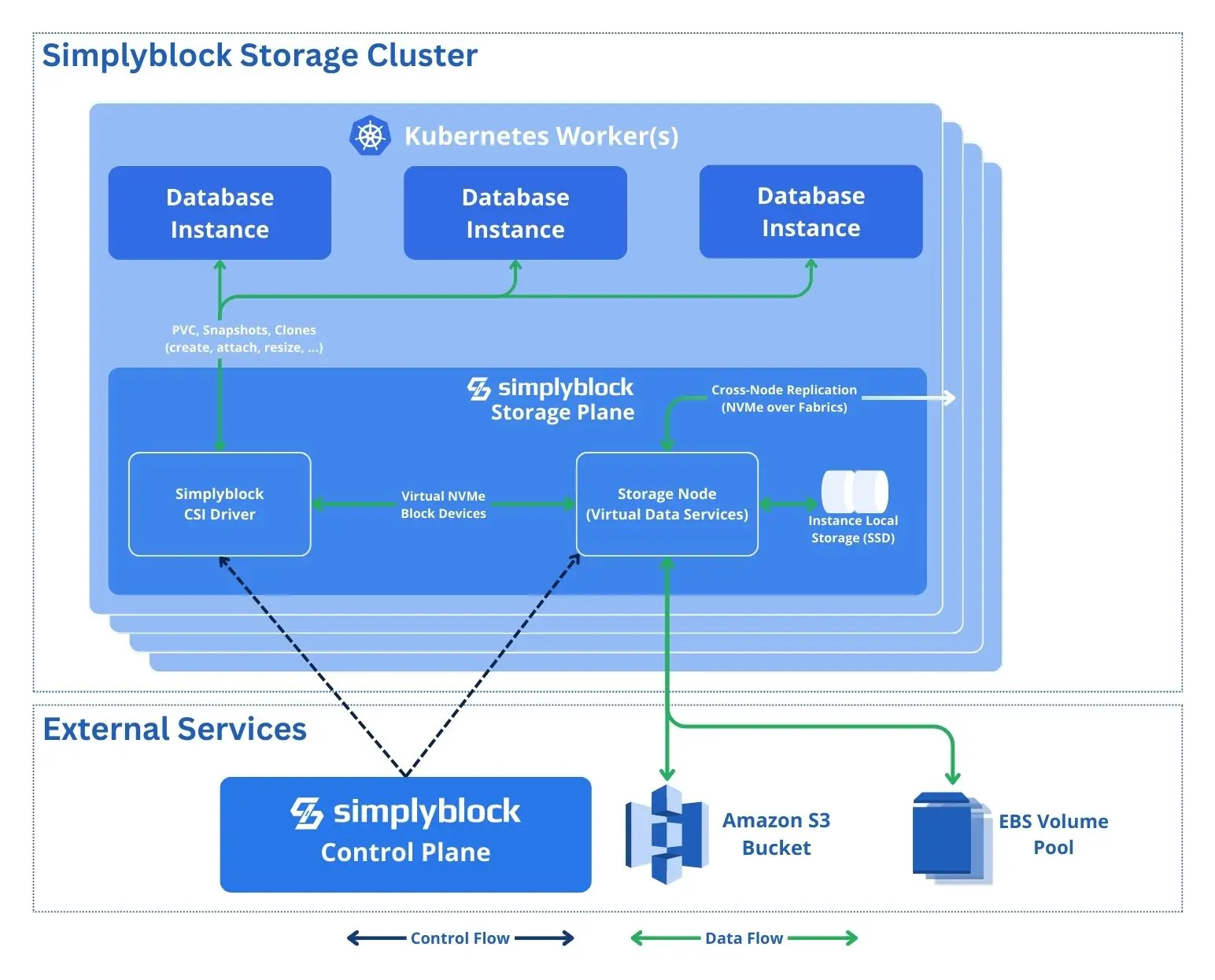
Stateful workloads, like Postgres or MySQL, can scale out by adding additional read-replicas to the cluster. However, every single instance needs storage to store its very own data. Hence, the need for scalable storage arrives.
Simplyblock is a cloud-native and distributed storage platform built to deliver scalable performance and virtually infinite capacity for logical devices through horizontal scalability. Unlike traditional storage systems, simplyblock distributes data across all cluster nodes, multiplying the performance and capacity.
Designed as an NVMe-first architecture, simplyblock using the NVMe over Fabrics protocol family. This extends the reach of the highly scalable NVMe protocol over network fabrics such as TCP, Fibre Channel, and others. Furthermore, it provides built-in support for multi-pathing, enabling seamless failover and load balancing.
The system uses a distributed data placement algorithm to spread data across all available cluster nodes, automatically rebalancing data when nodes are added or removed. When writing data, simplyblock splits the item into multiple, smaller chunks and distributes them. This allows for parallel access during read operations. The data distribution also provides redundancy, with parity information stored on other nodes in the cluster. This protects the data against individual disk and node failures.
Using this architecture, simplyblock provides linear capacity and performance scalability by pooling all available disks and parallelizing access. This enables simplyblock to scale from mere terabytes to multiple petabytes while maintaining performance, consistency, and durability characteristics throughout the cluster-growth process.
Building Future-Proof Infrastructure
To wrap up, when you build out a new system infrastructure or application, consider these facts:
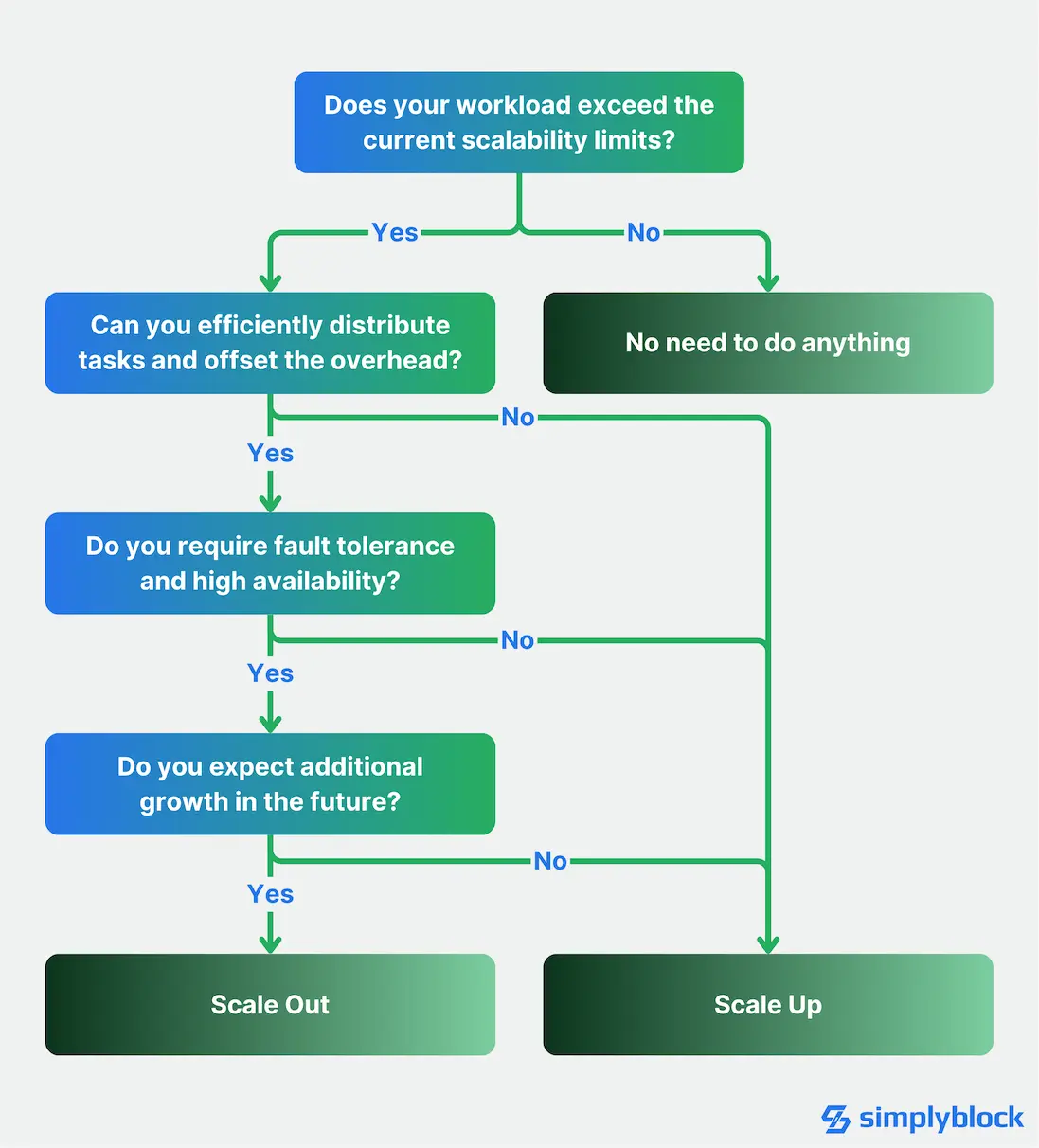
- Workload characteristics: CPU-intensive workloads might benefit more from vertical scaling. Distributing operations comes with its own overhead. If the operation itself doesn’t set off this overhead, you might see lower performance than with vertical scaling. On the other hand, I/O-heavy workloads might perform better with horizontal scaling. If the access patterns are highly parallelizable, a horizontal architecture will most likely out scale a vertical one.
- Growth patterns: Predictable, steady growth might favor scaling up, while rapid growth patterns might necessitate the flexibility of scaling out. This isn’t a hard rule, though. A carefully designed scale-out system will provide a very predictable growth pattern and latency. However, the application isn’t the only element to take into account when designing the system, as there are other components, most prominently the network and network equipment.
- Future-Proofing: Scaling out often requires little upfront investment in infrastructure but higher investment in development and expertise. It can, however, provide better long-term cost efficiency for large deployments. That said, buying a scale-out solution is a great idea. With a storage solution like simplyblock, for example, you can start small and add required resources whenever necessary. With traditional storage solutions, you have to go with a higher upfront cost and are limited by the physical ceiling.
- Operational Complexity: Scale-up architectures are typically easier to manage, while a stronger DevOps or operations team is required to handle scale-out solutions. That’s why simplyblock’s design is carefully crafted to be fully autonomous and self-healing, with as few hands-on requirements as possible.
The Answer Depends
That means there is no universal answer to whether scaling up or out is better. A consultant would say, “It depends.” Seriously, it does. It depends on your specific requirements, constraints, and goals.
Many successful organizations use a hybrid approach, scaling up individual nodes while also scaling out their overall infrastructure. The key is understanding the trade-offs and choosing the best approach to your needs while keeping future growth in mind. Hence, simplyblock provides the general scale-out architecture for infinite scalability. It also provides a way to utilize storage located in Kubernetes worker nodes as part of the storage cluster to provide the highest possible performance. At the same time, it maintains the option to spill over when local capacity is reached and the high durability and fault tolerance of a fully distributed storage system.
Remember, the best scaling strategy aligns with your business objectives while maintaining performance, reliability, and cost-effectiveness. Whether you scale up, out, or both, ensure your choice supports your long-term infrastructure goals.
Questions and Answers
Scale-up storage increases capacity by adding more hardware to a single system, while scale-out adds more nodes to a distributed system. Scale-out architectures are better for flexibility, fault tolerance, and linear scalability in cloud-native environments.
Use scale-out when your workloads demand high availability, elasticity, or run on Kubernetes or distributed systems. It’s ideal for large datasets, analytics, and modern apps that require seamless growth and horizontal scaling.
Not necessarily. While scale-out may seem complex, it often uses commodity hardware and avoids overprovisioning. With efficient storage management, it can reduce total cost of ownership over time.
Yes, Kubernetes thrives with scale-out storage due to its distributed, containerized nature. Platforms like Simplyblock offer dynamic provisioning and NVMe-over-TCP for scalable performance and seamless integration with container workloads.
Absolutely. Many organizations transition to scale-out over time as data demands grow. Software-defined storage like simplyblock enables gradual migration without service disruption, making it easy to modernize your infrastructure.


