
“Cloud is expensive” is an often repeated phrase among IT professionals. What makes the cloud so expensive, though? One element that significantly drives cloud costs is storage over-provisioning and lack of storage optimization. Over-provisioning refers to the eager allocation of more resources than required by a specific workload at the time of allocation.
When we hear about hoarding goods, we often think of so-called preppers preparing for some type of serious event. Many people would laugh about that kind of behavior. However, it is commonplace when we are talking about cloud environments.
In the past, most workloads used their own servers, often barely utilizing any of the machines. That’s why we invented virtualization techniques, first with virtual machines and later with containers. We didn’t like the idea of wasting resources and money.
That didn’t stop when workloads were moved to the cloud, or did it?
What is Over-Provisioning?
As briefly mentioned above, over-provisioning refers to allocating more resources than are needed for a given workload or application. That means we actively request more resources than we need, and we know it. Over-provisioning typically occurs across various infrastructure components: CPU, memory, and storage. Let’s look at some basic examples to understand what that means:
- CPU Over-Provisioning: Imagine running a web server on a virtual machine instance (e.g., Amazon EC2) with 16 vCPUs. At the same time, your application only requires four vCPUs for the current load and number of customers. You expect to increase the number of customers in the next year or so. Until then, the excess computing power sits idle, wasting resources and money.
- Memory Over-Provisioning: Consider a database server provisioned with 64GB of RAM when the database service commonly only uses 16GB, except during peak loads. The unused memory is essentially paid for but unutilized most of the time.
- Storage Over-Provisioning: Consider a Kubernetes cluster with ten instances of the same stateful service (like a database), each requesting a block storage volume (e.g., Amazon EBS) of 100 GB but will only slowly fill it up over the course of a year. In this case, each container uses about 20 GB as of now, meaning we over-provisioned 800 GB, and we have to pay for it.
Why is EBS Over-Provisioning an Issue?
EBS Over-provisioning isn’t an issue by itself, and we lived happily ever after (almost) with it for decades. While over-provisioning seems to be the safe bet to ensure performance and plannability, it comes with a set of drawbacks.
- High initial cost: When you overprovision, you pay for resources you don’t use from day one. This can significantly inflate your cloud bill, especially at scale.
- Resource waste: Unused resources aren’t just a financial burden. They also waste valuable computing power that could be better allocated elsewhere. Not to mention the environmental effects of over-provisioning, think CO2 footprint.
- Hard to estimate upfront: Predicting exact resource needs is challenging, especially for new applications or those with variable workloads. This uncertainty often leads us to very conservative (and excessive) provisioning decisions.
- Limitations when resizing: While cloud providers like AWS allow resource resizing, limitations exist. Amazon EBS volumes can only be modified every 6 hours, making it difficult to adjust to changing needs quickly.
On top of those issues, which are all financial impact related, over-provisioning can also directly or indirectly contribute to topics such as:
- Reduced budget for innovation
- Complex and hard-to-manage infrastructures
- Potential compliance issues in regulated industries
- Decreased infrastructure efficiency
The Solution is Pay-By-Use
Pay-by-use refers to the concept that customers are billed only for what they actually use. That said, using our earlier example of a 100 GB Amazon EBS volume where only 20 GB is used, we would only be charged for those 20 GB. As a customer, I’d love the pay-by-use option since it makes it easy and relieves me of the burden of the initial estimate.
So why isn’t everyone just offering pay-by-use models?
The Complexity of Pay-By-Use
Many organizations dream of an actual pay-by-use model, where they only pay for the exact resources consumed. This improves the financial impact, optimizes the overall resource utilization, and brings environmental benefits. However, implementing this is challenging for several reasons:
- Technical Complexity: Building a system that can accurately measure and bill for precise resource usage in real time is technically complex.
- Performance Concerns: Constant scaling and de-scaling to match exact usage can potentially impact performance and introduce latency.
- Unpredictable Costs: While pay-by-use can save money, it can also make costs less predictable, making budgeting challenging.
- Legacy Systems: Many existing applications aren’t designed to work with dynamically allocated resources.
- Cloud Provider Greed: While this is probably exaggerated, there is still some truth. Cloud providers overcommit CPU, RAM, and network bandwidth, which is why they offer both machine types with dedicated resources and ones without (where they tend to over-provision resources, and you might encounter the “noisy neighbor” problem). On the storage side, they thinly provision your storage out of a large, ever-growing storage pool.
Over-Provisioning in AWS
Like most cloud providers, AWS has several components where over-provisioning is typical. The most obvious one is resources around Amazon EC2. However, since many other services are built upon EC2 machines (like Kubernetes clusters), this is the most common entry point to look into optimization.
Amazon EC2 (CPU and Memory)
When looking at Amazon EC2 instances to save some hard-earned money, AWS offers some tools by itself:
- Use AWS CloudWatch to monitor CPU and memory utilization.
- Implement auto-scaling groups to adjust instance counts dynamically based on demand.
- Consider using EC2 Auto Scaling with predictive scaling to anticipate future needs.
In addition, some external tools, such as AutoSpotting or Cast.ai, enable you to find over-provisioned VMs and adjust them accordingly automatically or exchange them with so-called spot instances. Spot instances are VM instances that are way cheaper but can be taken away from you with only a few seconds’ notice. The idea is that AWS offers these instances at a reduced rate when they can’t be sold for their regular price. That said, if the capacity is required, they’ll take them away from you—still a great way to save some money.
Last but not least, companies like DoIT work as resellers for hyperscalers like AWS. They have custom rates and offer additional features like bursting beyond your typical requirements. This is a great way to get cheaper VMs and extra services. It’s worth a look.
Amazon EBS Storage Over-Provisioning
One of the most common causes of over-provisioning happens with block storage volumes, such as Amazon EBS. With EBS, the over-provisioning is normally driven by:
- Pre-allocated Capacity: EBS volumes are provisioned with a fixed size, and you pay for the entire allocated space regardless of usage.
- Modification Limitations: EBS volumes can only be modified every 6 hours, making rapid adjustments difficult.
- Performance Considerations: A common belief is that larger volumes perform better, so people feel incentivized to over-provision.
One interesting note, though, is that while customers have to pay for the total allocated size, AWS likely uses technologies such as thin provisioning internally, allowing it to oversell its actual physical storage. Imagine this overselling margin would be on your end and not the hyperscaler.
How Simplyblock Can Help with EBS Storage Over-Provisioning
Simplyblock offers an innovative storage optimization platform to address storage over-provisioning challenges. By providing you with a comprehensive set of technologies, simplyblock enables several features that significantly optimize storage usage and costs.
Thin Provisioning
Thin provisioning is a technique where a storage entity of any capacity will be created without pre-allocating the requested capacity. A thinly provisioned volume will only require as much physical storage as the data consumes at any point in time. This enables overcommitting the underlying storage, like ten volumes with a provisioned capacity of 1 TB each. Still, only 100GB being used will require around 1 TB at this time, meaning you can save around 9 TB of storage that is not paid for unless used.
Simplyblock’s thin provisioning technology allows you to create logical volumes of any size without pre-allocating the total capacity. You only consume (and pay for) the actual space your data uses. This eliminates the need to over-provision “just in case” and allows for more efficient use of your storage resources. When your actual storage requirements increase, simplyblock automatically allocates additional underlying storage to keep up with your demands.

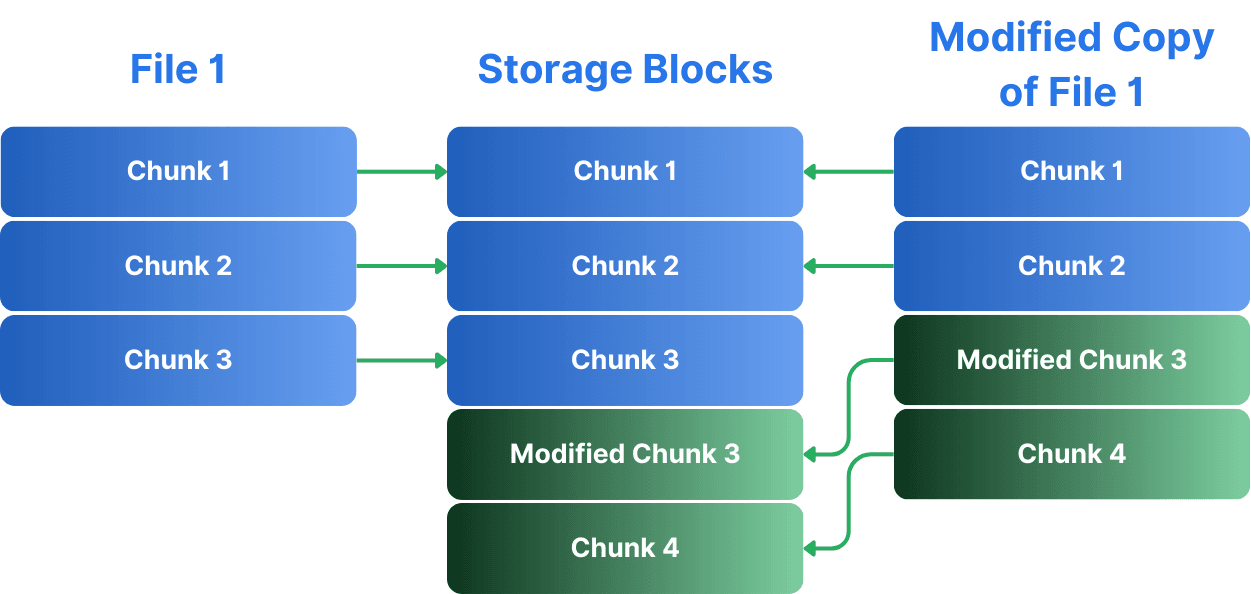
Copy-on-Write, Snapshots, and Instant Clones
Simplyblock’s storage technology is a fully copy-on-write-enabled system. Copy-on-write is a technique also known as shadowing. Instead of copying data right away when multiple copies are created, copy-on-write will only create a second instance when the data is actually changed. This means the old version is still around since other copies still refer to it, while only one specific copy refers to the changed data. Copy-on-write enables the instant creation of volume snapshots and clones without duplicating data. This is particularly useful for development and testing environments, where multiple copies of large datasets are often needed. Instead of provisioning full copies of production data, you can create instant, space-efficient clones specifically attractive for databases, AI / ML workloads, or analytics data.
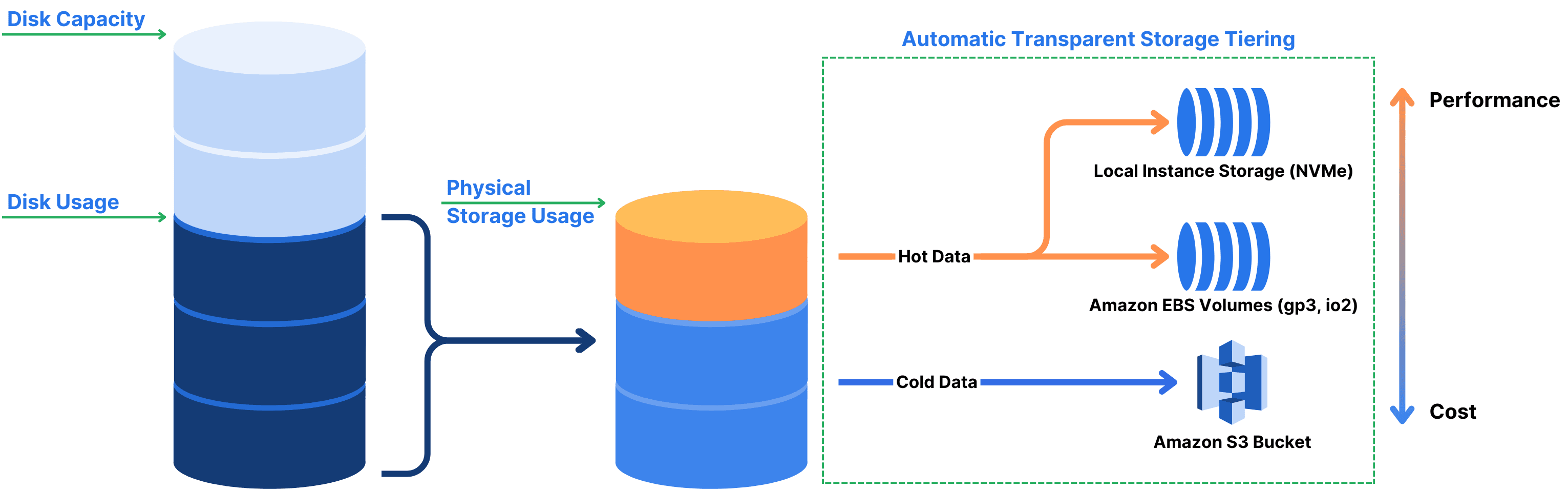
Transparent Tiering
With most data sets, parts of the data are typically assumed to be “cold,” meaning that the data is very infrequently used, if ever. This is true for any data that needs to be kept available for regulatory reasons or historical manufacturing data (such as process information for car part manufacturing). This data can be moved to slower but much less expensive storage options. Simplyblock automatically moves infrequently accessed data to cheaper storage tiers such as object storage (e.g., Amazon S3 or MinIO) and non-NVMe SSD or HDD pools while keeping hot data on high-performance storage. This tiering is completely transparent to your applications, database, or other workload and helps optimize costs without sacrificing performance. With tiering integrated into the storage layer, application and system developers can focus on business logic rather than storage requirements.
Storage Pooling
Storage pooling is a technique in which multiple storage devices or services are used in conjunction. It enables technologies like thin provisioning and data tiering, which were already mentioned above.
By pooling multiple cloud block storage volumes (e.g., Amazon EBS volumes), simplyblock can provide better performance and more flexible scaling. This pooling allows for more granular storage growth, preventing the provision of large EBS volumes upfront.
Additionally, simplyblock can leverage directly attached fast SSD storage (NVMe), also called local instance storage, and make it part of the storage pool or use it as an even faster workload-local data cache.
NVMe over Fabrics
NVMe over Fabrics is an industry-standard for remotely attaching block devices to clients. It can be assumed to be the successor of iSCSI and enables the full feature set and performance of NVMe-based SSD storage. Simplyblock uses NVMe over Fabrics (specifically the NVMe/TCP version) to provide high-performance, low-latency access to storage.
This enables the consolidation of multiple storage locations into a centralized one, enabling even greater savings on storage capacity and compute power.
Pay-By-Use Model Enablement
As stated above, pay-by-use models are a real business advantage, specifically for storage. Implementing a pay-by-use model in the cloud requires taking charge of how storage works. This is complex and requires a lot of engineering effort. This is where simplyblock helps bring a competitive advantage to your doorstep.
With its underlying technology and features such as thin provisioning, simplyblock makes it easier for managed service providers to implement a true pay-by-use model for their customers, giving you the competitive advantage at no extra cost or development effort, all fully transparent to your database or application workload.
AWS Storage Optimization with Simplyblock
By addressing the core issues of EBS over-provisioning, Simplyblock helps reduce costs and improves overall storage efficiency and flexibility. For businesses undergoing AWS workload migration and struggling with storage over-provisioning, Simplyblock offers a compelling solution to optimize their infrastructure and better align costs with actual usage.
In conclusion, while over-provisioning remains a significant challenge in AWS environments, particularly with storage, Simplyblock paves the way for more efficient, cost-effective cloud storage optimization management. By combining advanced technologies with a deep understanding of cloud storage dynamics, Simplyblock enables businesses to achieve the elusive goal of paying only for what they use without sacrificing performance or flexibility, while also helping to reduce their cloud storage carbon footprint.
Take your competitive advantage and get started with simplyblock today.
Questions and Answers
Storage over-provisioning happens when allocated storage exceeds actual usage, leading to wasted capacity and higher costs. It’s a common issue in static volume provisioning and can be mitigated with dynamic provisioning and thin provisioning techniques.
Kubernetes users should rely on dynamic provisioning via CSI drivers, set realistic storage requests and limits, and use volume metrics to monitor utilization. Solutions like simplyblock support thin provisioning to only consume space that’s actually used.
Over-provisioning can inflate infrastructure costs, complicate scaling, and create false availability assumptions. It also increases backup and replication overhead, especially in distributed environments like databases on Kubernetes.
Thin provisioning allocates storage on-demand as data is written, while thick provisioning reserves the entire requested space up front. Thin provisioning is more efficient for cloud-native workloads and reduces waste when paired with software-defined storage.
Yes, simplyblock supports thin-provisioned volumes, dynamic scaling, and visibility into real-time usage. It’s designed for cloud cost optimization by helping teams match provisioned resources with actual needs in Kubernetes and beyond.


