

Storage management in Kubernetes can be complex, especially for teams running stateful workloads like databases. While K8s excels at container orchestration, its default ephemeral storage isn’t suitable for persistent data. This is where Kubernetes Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) become essential. Understanding how to manage persistent storage in K8s effectively is crucial for organizations operating databases or data-intensive applications.
Before diving into the implementation details, let’s first understand what persistent volumes are and why they matter for your Kubernetes workloads.
What are Persistent Volumes (PVs)?
Kubernetes Persistent Volumes are resources that provide storage for your pods. A single PV represents a single logical storage entity, such as a directory or block storage device, and can be ephemeral or persistent. Persistent volumes are either bound to the lifecycle of the Pod and are created, updated, and deleted automatically, respective to the Pod’s lifecycle, or they are managed manually.
One of the advantages of K8s is its extensibility and, with that, to deploy applications with the resources they need. By default, application Pods created by Kubernetes have readable and writable disk space. However, this disk space is ephemeral and will disappear
The Concept of Kubernetes Volumes
Kubernetes manages storage for Pods and containers through volumes. The concept is similar to partitions on hard disks, where a larger entity is broken into smaller entities that can be used “somewhat” independently. That said, a Kubernetes Volume is a way to define storage for data.
A volume in K8s introduces the separation of concerns between the actual storage and the Pod, making it possible to utilize a wide variety of storage providers. You can use storage solutions ranging from ephemeral, temporary storage over local directory mounts and object storage providers to local or remote block storage devices. The former is ephemeral storage, and the latter option is persistent storage (meaning the content stored survives a restart).
In Kubernetes, Persistent volumes are either created manually (statically) by an administrator or dynamically through a Persistent Volume Claim, but for now, we want to go the manual route.
apiVersion: v1
kind: PersistentVolume
metadata:
name: postgres-wal-vol-pv
spec:
storageClassName: sb-unlimited-encrypted
capacity: 20Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
In the example, we create a new persistent volume with 20 GB capacity. ReadWriteOnce tells Kubernetes that only one cluster node can access this PV. However, all Pods on that node may access it.
Depending on your requirements, there are other values for the access permissions:
- ReadWriteOnce (RWO): Allows all pods on a single node to mount the volume in read-write mode.
- ReadWriteMany (RWX): Allows multiple pods on multiple nodes to read and write to the volume. Remember, this could be dangerous for databases and other applications that don’t support a shared state.
- ReadOnlyMany (ROX): Allows multiple pods on multiple nodes to read the volume. Very practical for a shared configuration state.
- ReadWriteOncePod: Allows a single pod to read-write mount the volume on a single node.
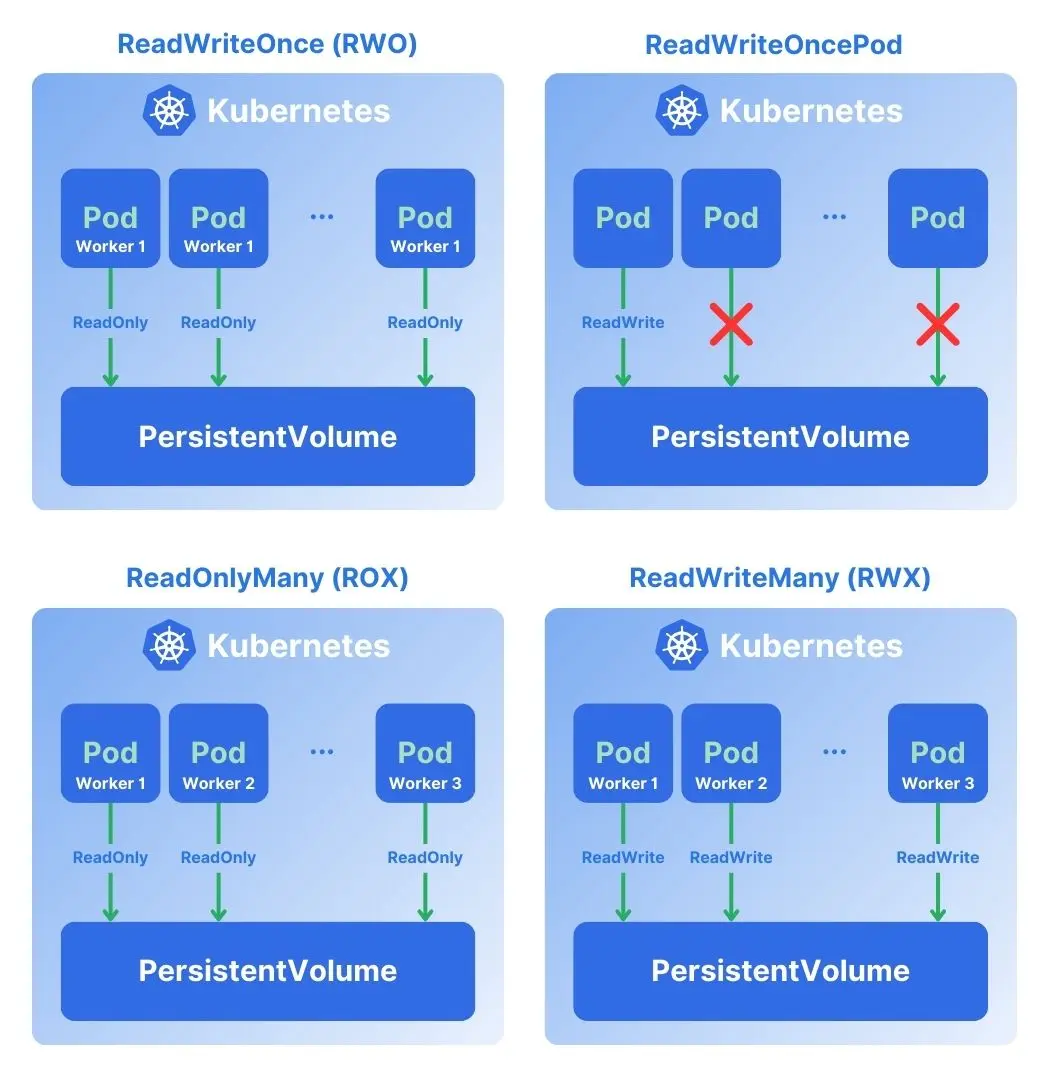
An important note, though, is that not all storage providers (CSI driver implementations) support all modes.
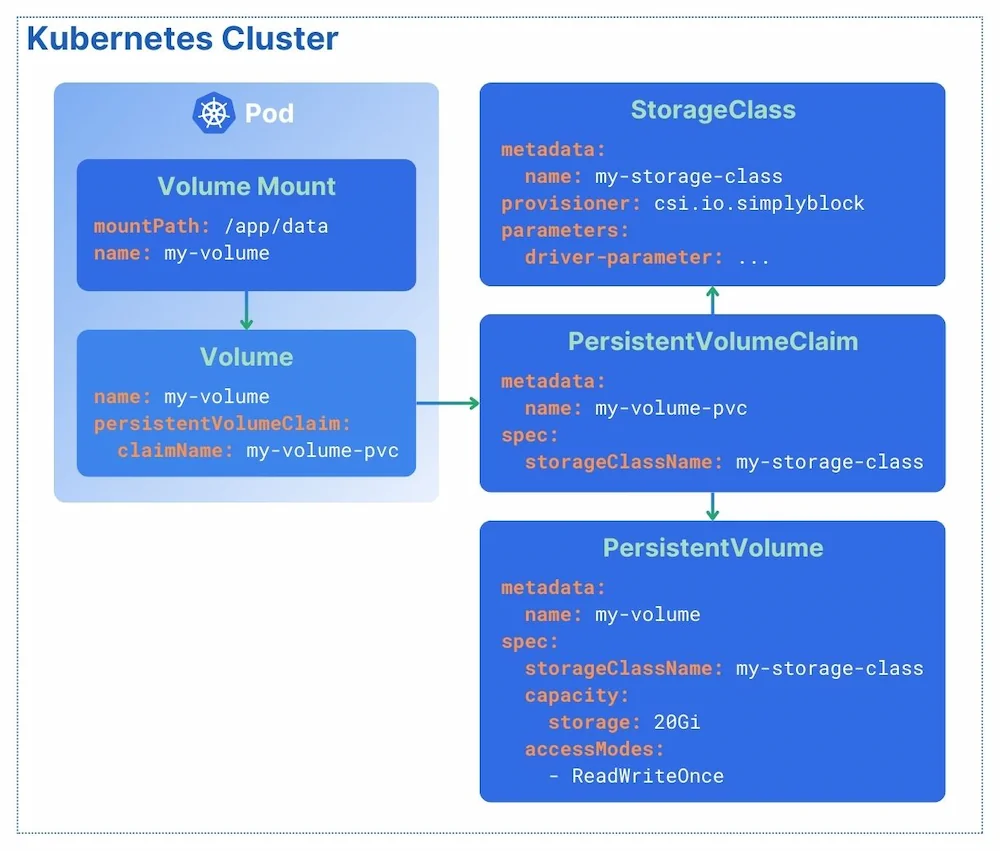
What is a Persistent Volume Claim (PVC)?
The Persistent Volume Claim is the actual request to mount a persistent volume into a Kubernetes pod. The idea is to separate the concern of “I need storage” from the deployment of the actual storage backend. The operations team can handle the latter, deploying a storage cluster and providing the necessary StorageClass, probably even defining a StorageClass default value if none is configured. That way, all default requests will be fulfilled through the default storage class, while specific requirements (such as those for a database) can be made explicit.
Statically Provisioned Persistent Volume
The PVC either refers to a statically provisioned persistent volume or can provision it dynamically when consumed by a pod. Binding a persistent volume claim to a statically provisioned persistent volume is in Kubernetes as simple as the following example:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-wal-vol-pvc
spec:
storageClassName: "" # Explicitly disable dynamic provisioning
volumeName: postgres-wal-vol-pv # Volume reference
To bind a persistent volume claim to our pre-created volume, we need to refer to it. The PVC will remain in an unresolved state, waiting for the requested persistent volume to become available.
Dynamically Provisioned Persistent Volume
To support dynamic provisioning of the persistent volume, if not available, we can either remove the storageClassName property and get the default storage class or specify one explicitly. In either case, the underlying persistent volume will automatically be created using the storage class of choice and be bound to the requesting PVC.
In this case, most of the Kubernetes persistent volume configuration will be moved to the persistent volume claim:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-wal-vol-pvc
spec:
storageClassName: sb-unlimited-encrypted
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
What is a StorageClass?
To make a storage provider available to Kubernetes, a so-called StorageClass is used. A StorageClass contains multiple configuration values to describe characteristics such as storage capacity and performance. When creating a volume (ephemeral or persistent), the PV is configured (implicitly or explicitly) using the StorageClass of choice, and the underlying storage provider will take care of provisioning and the volume’s lifecycle.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sb-unlimited-encrypted
provisioner: csi.simplyblock.io
parameters:
csi.storage.k8s.io/fstype: ext4
pool_name: testing1
qos_rw_iops: "0"
qos_rw_mbytes: "0"
qos_r_mbytes: "0"
qos_w_mbytes: "0"
compression: "False"
encryption: "True"
distr_ndcs: "1"
distr_npcs: "1"
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
In the above example, one StorageClass resource is defined. It uses the simplyblock CSI driver (csi.simplyblock.io). CSI stands for Container Storage Interface and is the official Kubernetes standard for implementing storage providers to interact with. Imagine it to be a set of required and optional operations that can be executed on a volume (like provisioning, snapshotting, and deleting). The benefit of storage classes is that the same storage provider may be used to implement multiple different volume characteristics. In the above example, the storage class is named “sb-unlimited-encrypted.” It isn’t rate-limited in any way and can go as fast as possible. It is, however, encrypted. In a second one, sb-10mbps-encrypted, we may want to limit the speed, for example, to ensure that boot volumes can’t cannibalize the performance of volumes used for database storage.
Anyhow, while the spec defines a good chunk of the StorageClass properties, the storage provider defines the parameter properties themselves. Therefore, when creating storage classes, make sure to look up the storage providers’ documentation for a reference of all available properties.
Lifecycle of a Kubernetes Persistent Volume and Persistent Volume Claim
Like all resources inside Kubernetes, PVs and PVCs have their own lifecycle, sometimes directly depending on other resources, such as pods.
During this lifecycle, a persistent volume is in one of the following stages:
- Provisioning: The persistent volume is being provisioned, either statically or dynamically.
- Binding: The PVC is being bound to a PVC. This happens when the administrator either creates a PVC manually consuming the PV or, in the case of dynamic provisioning, it is bound to the requesting PVC.
- Using: A pod consumes the PV and PVC. That doesn’t mean that a PV is actively used (in the sense that it has active read-write operations), but it is mounted into a running container.
- Reclaiming: If a reclaim policy is configured, Kubernetes will reclaim the volume once the user is done with it. Depending on the policy, the volume is either retained (meaning the PV will not be deleted together with the PVC), deleted (the volume will be deleted together with the PVC), or recycled (this approach is deprecated; don’t use it).
Important note: If a persistent volume claim is deleted while the bound persistent volume is still attached to a running pod, the persistent volume claim isn’t immediately removed but scheduled for removal once the pod has shut down.
Not less important, though, is if you want to reuse a PV after it is reclaimed with the retained policy, this will only work for statically created PVs. Also, make sure that your PV doesn’t have the claimRef property. We didn’t mention that property before since dynamic provisioning is the recommended way of creating persistent volumes.
Best Practices
When using persistent volumes and volume claims, there are a few things to remember. While this isn’t an exhaustive list, these are the rules I ran by when we were using Kubernetes at my own startup and previous companies.
Kubernetes PV and PVC – best practices
Utilize dynamic provisioning as much as possible. Situations where you want to provision a PV statically are rare. Always ask yourself if you do the right thing when you want to use it. Define a default StorageClass, commonly used in most volumes. It should be fast enough for common logging and other features. If you need something faster for specific cases, consider a separate storage class, which will be explicitly defined in the request. Consider your options in terms of storage providers (CSI drivers). Like always, the one-fits-all category of solutions is uncommon. Kubernetes provides you with everything you need to employ multiple storage providers. Use the best tool for the job.
CSI Drivers for Kubernetes
There is a searchable list of available CSI providers available. Consider if ephemeral storage may be enough for certain volumes. If your application has persistent and non-persistent storage requirements, enable it to use different volumes. When configuring storage classes, make sure to use appropriate parameters. Always double-check the vendor’s documentation for available parameters. Make sure to use appropriate access modes. If a pod doesn’t need write access, you shouldn’t provide it with such. Just a small bit of security, but every bit counts. Along the same lines, encrypt data at rest (and in transit) if available! Make sure you configure the reclaim policy. You don’t want to suddenly run out of storage with just one pod because you never reclaimed the storage of previous ones. Implement storage quotas and limits. Most CSI drivers offer expandable volumes and make good use of them for resource planning and controlling.
If you feel like I totally missed something, please let me know on X/Twitter or Mastodon. Also, remember to follow simplyblock on X 😁
Final thoughts
Kubernetes storage is complex but not complicated. The important bit to understand is that a pod uses a PVC to be paired with a PV. If the persistent volume doesn’t exist yet, Kubernetes will dynamically provision and bind it. If the pod is removed, the persistent volume claim and persistent volume will be removed, respectively (except defined differently). That makes storage management ideal for applications with a need for persistent storage, such as databases, applications for file sharing, systems that need to share state, or AI and machine learning use cases.
Simplyblock offers a highly scalable, latency-optimized disaggregated storage for the most demanding of such applications. Disaggregated means that storage and compute are scaled independently of each other, making it much more cost-effective than hyper-converged storage. Furthermore, simplyblock provides thin provisioning, storage tiering, and immediate snapshots alongside a Kubernetes CSI driver and many more features. Learn more about simplyblock, or try it out now.