
Software-defined (block) storage solutions, or SDS, decouple the software storage layer from the underlying hardware. This allows for centralized management and automation of storage resources through the software abstraction layer and enables performant and simplified deployments of block, file, and object storage.
Unlike traditional storage solutions, which typically rely heavily on proprietary hardware, software-defined storage leverages commodity hardware and virtualization technologies. Software-defined storage enables companies to deploy, operate, and scale storage resources with greater flexibility and cost efficiency.
How Software-Defined Storage Works
Software-defined storage is, first and foremost, software that abstracts the hardware from data management and visible data storage. This enables a high degree of flexibility when choosing storage hardware and provides the potential to build a storage solution that perfectly fits one’s needs in terms of performance, capacity, and scalability requirements.
Software-defined storage has multiple facets. It is sometimes bundled as a full operating system (often based on Linux or FreeBSD) or as a software layer installed on a common OS (most commonly Linux) installation. In either case, the physical hardware is managed by a general-purpose operating system, while the storage management is delivered in software.
To run software-defined storage, a suitable hardware or virtualization platform needs to be selected. Depending on the SDS solution, virtual cloud hosts (e.g., AWS Amazon EC2, Google Compute Engine VMs, or similar), on-premise virtual machines such as VMware VMs, or physical, dedicated storage servers can be used. Either way, the “physical” layer provides the actual storage capacity.
Software-Defined Storage is Not…
While software-defined storage is often used as a synonym for storage virtualization, that isn’t actually true. Storage virtualization defines the capability to combine and pool multiple local or remote storage devices into a single, large storage pool. For that reason, many SDS solutions are also storage virtualization solutions to some extent, hence the mix-up of the individual terms. However, building an SDS solution without the storage pooling option is perfectly possible.
Software-defined storage is also not a SaaS (Software as a Service) or IaaS (Infrastructure as a Service) solution. While it can be provided as a hosted and managed platform, it is more often not and is operated by the customer directly. That comes down to multiple factors, such as data privacy concerns or regulatory requirements, as well as specific configuration requirements.
Last but not least, software-defined storage isn’t necessarily a NAS (Network Attached Storage) or SAN (Storage Area Network). Since an SDS isn’t required to be built from a cluster of storage nodes or even a set of storage drives, there is no requirement to be able to pool them into a single storage space. In addition, an SDS solution isn’t necessarily connected through a network interconnect to the host machine, which consumes the storage. That said, while both SAN and NAS aren’t factual ingredients of SDS, just like storage virtualization, they are often part of the SDS solution for a broader set of use cases and increased flexibility.
Before and After: Software-Defined Storage vs Traditional Storage
Traditional enterprise storage setups are often based on proprietary hardware, meaning that multiple different storage systems are collected over time. These systems are often incompatible with each other, making it much harder to scale them or migrate between different solutions. That means that, more often than not, the setup gets stuck in time while new machines or generations are acquired for new use cases.
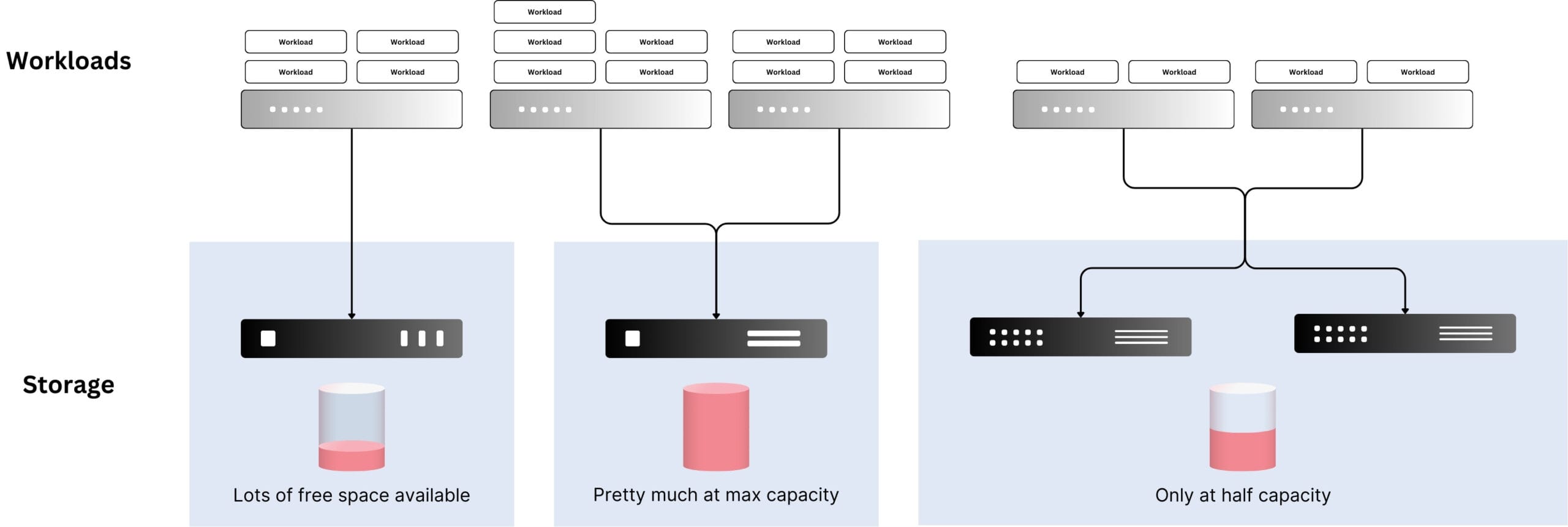
That leads to imbalanced use of the available storage resources. While some are at their capacity limit, others idle with plenty of unused free space. Migration between vendors or hardware generations is often complicated.
On the other hand, thanks to software-defined storage solutions, we have much more flexibility in terms of setups. Most SDS solutions feature storage virtualization (as mentioned above), which enables pooling the available storage resources and providing slices of them to the individual use cases.
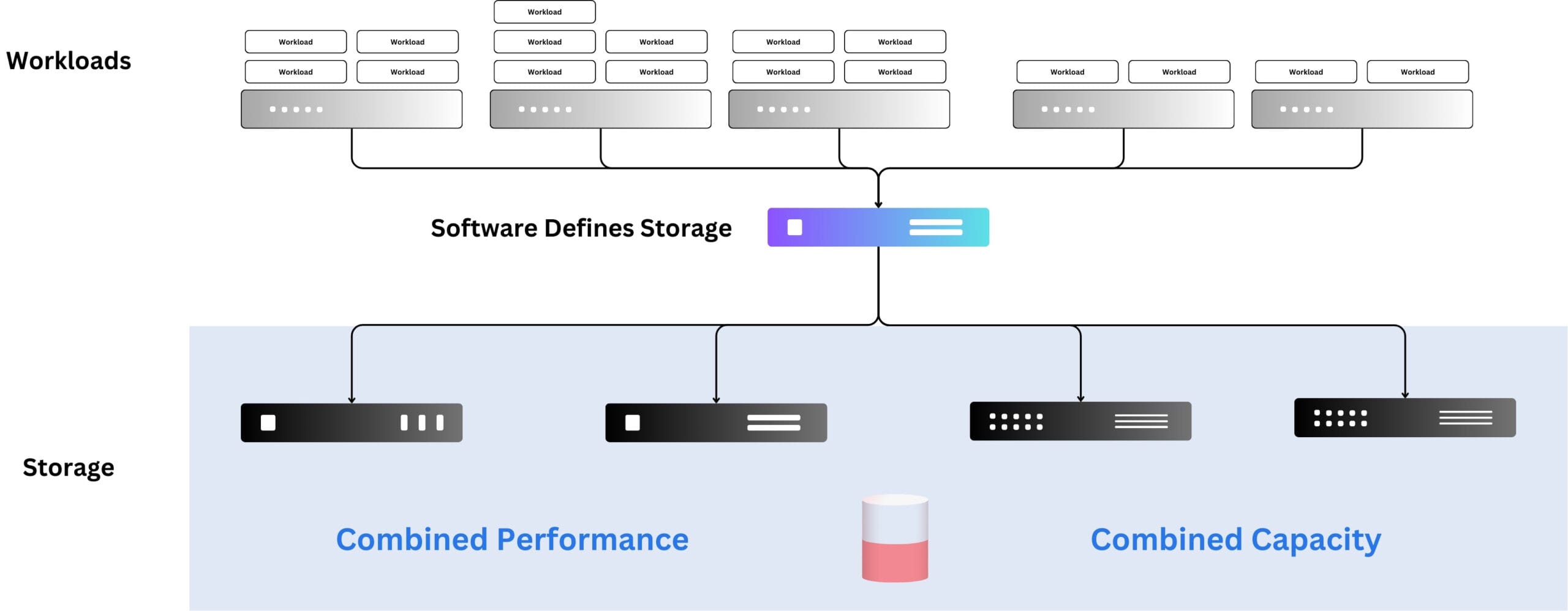
These slices (e.g., logical block storage or any other pattern of storage type) can differ in capacity, performance characteristics, and even storage type. Depending on the software-defined storage in use, one or more of the typical storage types (file storage, block storage, and blob/object storage) may be available to workloads.
Due to the nature of storage pooling, migrations between the underlying, abstracted hardware are easy and normally (automatically) handled by the SDS. The same is true for scalability. If free available storage gets sparse, additional storage hardware can be added. Depending on the solution in place, this can be a seamless online operation or require downtime.
Benefits of Software-Defined Storage
With all that said, Software Defined Storage has some clear advantages over the traditional, hardware-based storage options.
- The unified storage layer enables flexibility and easy migration. From a consumer’s perspective, the logical devices look the same, no matter where and how they are stored on the abstracted hardware.
- The typically integrated storage pooling enabled a great degree of scalability. Starting small and adding additional hardware to the storage pool at a later point in time enables cost-effective storage usage without wasting unused capacity.
- Choosing your own hardware enables you to build storage systems that meet the requirements in terms of performance, reliability, and capacity. There is no vendor lock-in and no reliance on proprietary hardware.
- Overall, a typical software-defined storage solution enables the most cost-effective way to store data through optimized hardware configurations, storage pooling (storage virtualization), features like thin provisioning, and more.
Hyper-Converged Storage
Hyper-converged storage is a deployment pattern in which the storage solution is installed in the same cluster as the application. This consolidates storage, compute, and networking resources into a single integrated system.
This architecture co-locates storage with compute within a single cluster environment (most commonly Kubernetes). This simplifies management but often limits scalability and performance due to resource sharing with other use cases.
Hyper-converged storage solutions typically utilize distributed architectures and instance-local flash storage to deliver high throughput and low latency.
Disaggregated Storage
Disaggregated storage is an architecture in which storage resources are separated from compute resources, allowing them to be managed and scaled independently.
Unlike traditional storage systems where storage is tightly integrated with compute within individual servers or nodes, disaggregated storage pools storage resources separately from compute resources across a network.
Disaggregated storage enables easier scalability since storage resources and compute resources are distinct concerns and clusters. That means a storage cluster can be scaled up even if no additional compute resources are required. Many databases will grow over time, increasing the storage needs without additional compute power requirements.
Get the most out of your Storage with Simplyblock
Simplyblock is the next generation of software-defined block storage, enabling storage requirements for the most demanding workloads. Pooled storage and our distributed data placement algorithm enable high IOPS per Gigabyte density, low, predictable latency, and high throughput. Using erasure coding (a better RAID) instead of replicas helps minimize storage overhead without sacrificing data safety and fault tolerance.
Additional features include instant snapshots (full and incremental), copy-on-write clones, thin provisioning, compression, encryption, and many more. Simplyblock’s software-defined block storage meets your requirements before you set them. Get started using simplyblock right now, or learn more about our feature set.


