Neo4j in Cloud and Kubernetes: Advantages, Cypher Queries, and Use Cases
Jul 15th, 2024 | 9 min read

Table Of Contents
- Introduction:
- Why Choose Neo4j over Traditional Relational Databases?
- What are the Main Differences between Graph Databases and Relational Databases?
- How does Neo4j Handle Data Relationships Compared to SQL Databases?
- When should Developers Choose Neo4j over a Traditional Database?
- Simplifying Complex Data with Cypher Query Language
- How does Cypher Differ from SQL in Querying Complex Relationships?
- What are the Key Features of Cypher that Make it Ideal for Graph Databases?
- Neo4j use Cases in Cloud and Kubernetes Environments
- How does Neo4j Enhance Microservices Management in Kubernetes?
- What Advantages does Neo4j Offer for Fraud Detection in Cloud Environments?
- How can Neo4j Improve Supply Chain Management and Optimization?
- How Simplyblock Enhances Neo4j Performance in Kubernetes
- What Specific Performance Improvements can Neo4j Expect with Simplyblock?
- How does Simplyblock Ensure Data Integrity for Neo4j in Kubernetes?
- Can Simplyblock help Reduce Storage Costs for Neo4j Deployments?
Introduction:
In the era of big data, managing complex relationships is crucial. Neo4j , a leading graph database, excels at handling intricate data connections, making it indispensable for modern applications. This post explores Neo4j’s advantages, Cypher query language, and real-world applications in cloud and Kubernetes environments.
Why Choose Neo4j over Traditional Relational Databases?
Optimized for complex relationships Greater schema flexibility Intuitive data modeling Efficient query performance Natural data exploration
What are the Main Differences between Graph Databases and Relational Databases?
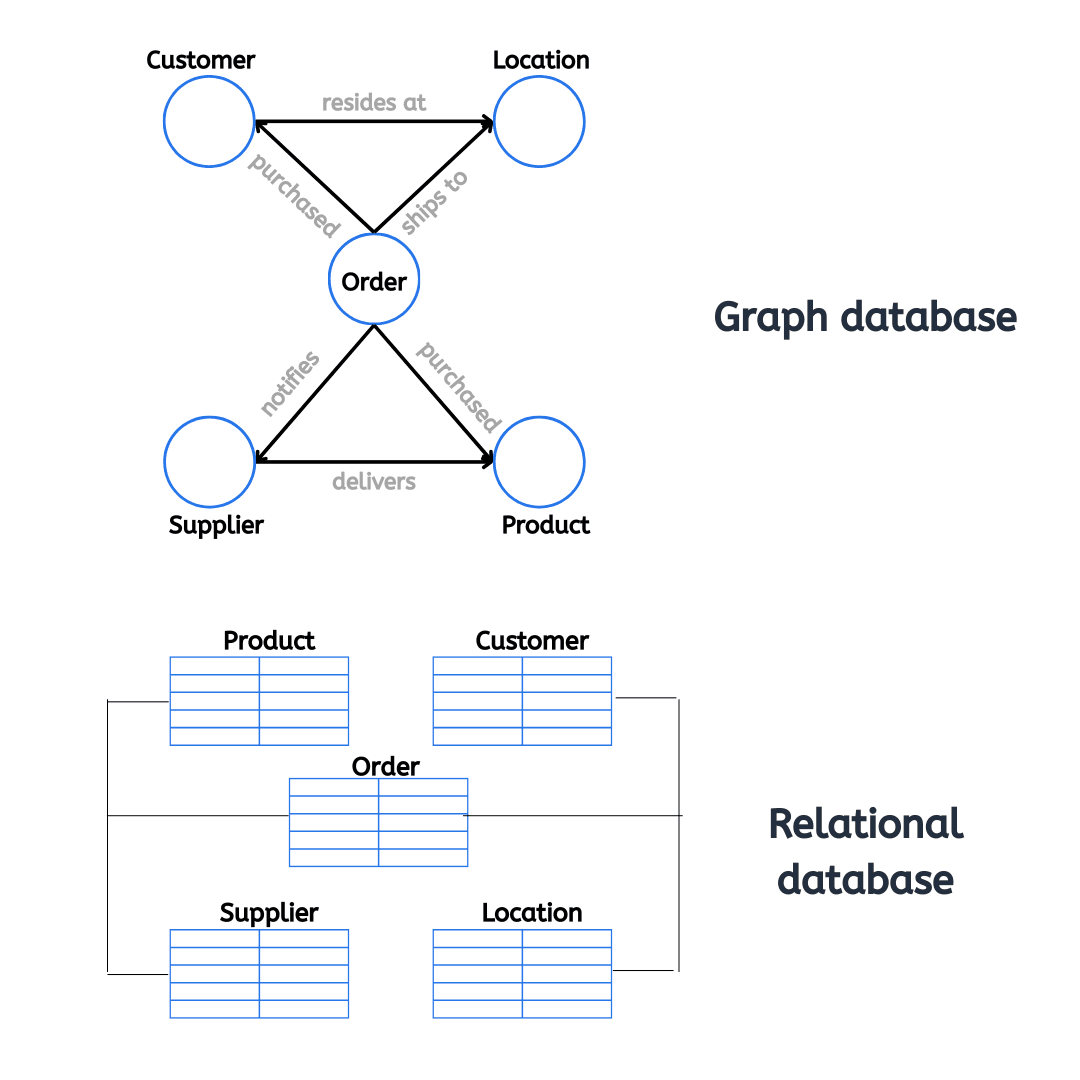
Graph databases and relational databases differ primarily in their structure and data retrieval methods. Graph databases excel at managing and querying relationships between data points, using nodes to represent entities and edges to illustrate connections. This structure is particularly useful for applications like social networks, fraud detection, and recommendation engines where relationships are key. In contrast, relational databases organize data into tables with rows and columns, focusing on structured data and using SQL (Structured Query Language) for CRUD operations (Create, Read, Update, Delete). Relational databases are ideal for applications requiring complex queries and transactions, such as financial systems and enterprise resource planning (ERP) solutions. Understanding these differences helps in selecting the appropriate database type based on specific application needs and data complexities.
How does Neo4j Handle Data Relationships Compared to SQL Databases?
Neo4j handles data relationships by using a graph-based model that directly connects data points (nodes) through relationships (edges). This allows for highly efficient querying and traversal of complex relationships without the need for complex JOIN-like operations (merges). Each relationship in Neo4j is stored as a first-class entity, making it easy to navigate and query intricate connections with minimal latency. In contrast, SQL databases manage relationships using foreign keys and JOIN operations across tables. While SQL databases are efficient for structured data and predefined queries, handling deeply nested or highly interconnected data often requires complex JOIN statements, which can be resource-intensive and slower. Neo4j’s graph model is specifically optimized for queries involving relationships, providing significant performance advantages in scenarios where understanding and traversing connections between data points is crucial.
When should Developers Choose Neo4j over a Traditional Database?
Developers should choose Neo4j over a traditional database when their application involves complex and dynamic relationships between data points. Neo4j’s graph-based model excels in scenarios such as social networking, recommendation systems, fraud detection, network and IT operations, and knowledge graphs, where understanding and querying intricate connections is critical. If the use case demands real-time querying and analysis of data relationships, such as finding the shortest path between nodes or traversing multi-level hierarchies efficiently, Neo4j provides superior performance and scalability compared to traditional relational databases. Additionally, Neo4j is advantageous when the data structure is flexible and evolves over time, as its schema-free nature allows for easy adaptation to changing requirements without significant reworking of the database schema. Choosing Neo4j can greatly enhance performance and simplify development in applications heavily reliant on interconnected data.
Simplifying Complex Data with Cypher Query Language
Cypher, Neo4j’s query language, streamlines data relationship management through:
- Intuitive syntax
- Declarative nature
- Powerful pattern matching
- Efficient recursion handling
- Built-in graph functions
- Advanced aggregation and filtering
- Seamless integration with graph algorithms
How does Cypher Differ from SQL in Querying Complex Relationships?
Cypher, the query language.) for Neo4j, differs from SQL in its intuitive approach to querying complex relationships. Cypher uses pattern matching to navigate through nodes and relationships, making it naturally suited for graph traversal and relationship-focused queries. For example, finding connections between nodes in Cypher involves specifying patterns that resemble the graph structure, making the queries concise and easier to understand.
In contrast, SQL relies on JOIN operations to link tables based on foreign keys, which can become cumbersome and less efficient for deeply nested or highly interconnected data. Complex relationships in SQL require multiple JOINs and subqueries, often leading to more verbose and harder-to-maintain queries.
Cypher’s declarative syntax allows developers to describe what they want to retrieve without specifying how to retrieve it, optimizing the underlying traversal and execution. This makes Cypher particularly powerful for applications needing to query and analyze intricate data relationships, such as social networks, recommendation engines, and network analysis, providing a clear advantage over SQL in these scenarios.
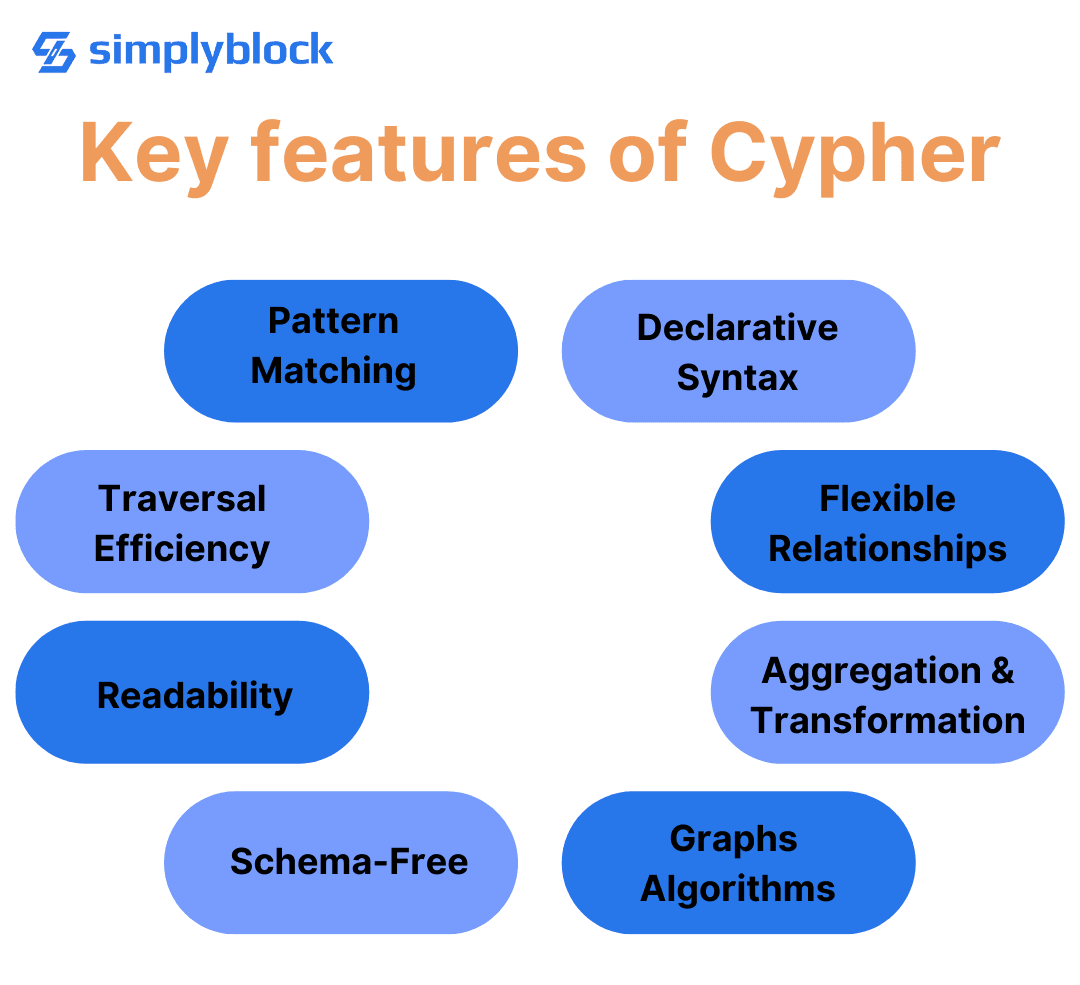
What are the Key Features of Cypher that Make it Ideal for Graph Databases?
Cypher is ideal for graph databases due to several key features:
- Pattern Matching : Allows intuitive querying by describing graph structures.
- Declarative Syntax : Simplifies complex queries, letting the engine optimize execution.
- Traversal Efficiency : Excels at navigating and exploring interconnected data.
- Flexible Relationships : Easily handles various types and attributes of relationships.
- Readability : Shorter, more readable queries compared to SQL’s JOIN operations.
- Aggregation and Transformation : Supports advanced data analysis functions.
- Schema-Free : Works well with dynamic, evolving data models.
- Graph Algorithms : Integrates with Neo4j’s built-in algorithms for advanced analytics. These features make Cypher a powerful language for managing and querying complex relationships in graph databases.
Neo4j use Cases in Cloud and Kubernetes Environments
- Microservices Management : Neo4j helps manage and visualize microservice architectures by tracking service dependencies and interactions by storing the relationships between each and every service, enhancing troubleshooting and system optimization.
- Fraud Detection : It identifies patterns and anomalies in transactional data, enabling real-time detection and prevention of fraudulent activities through relationship analysis.
- Identity and Access Management : Neo4j efficiently maps user permissions and roles, ensuring secure and scalable identity management and access control.
- IT Operations and Network Management : It monitors and optimizes IT infrastructure by mapping and analyzing network topologies, dependencies, and configurations.
- Recommendation Engines : Leveraging graph algorithms, Neo4j provides personalized recommendations by analyzing user preferences and relationships between items.
- Supply Chain Optimization : Neo4j optimizes supply chain processes by mapping product flows, identifying bottlenecks, and enhancing logistics management through relationship analysis.
- Healthcare Data Management : It manages complex healthcare data by integrating patient records, treatments, and outcomes, improving patient care and operational efficiency.
- Social Network Analysis : Neo4j uncovers insights into social networks by analyzing connections and interactions, supporting marketing, and user engagement strategies.
- Knowledge Graph Construction : It constructs and manages knowledge graphs, linking diverse data sources to provide a unified view and advanced search capabilities.
- Compliance and Regulatory Reporting : Neo4j ensures compliance by tracking data lineage, managing regulatory requirements, and generating comprehensive reports for audits and governance.
How does Neo4j Enhance Microservices Management in Kubernetes?
Neo4j enhances microservices management in Kubernetes by providing a clear visualization of service dependencies and interactions. It helps in tracking the relationships between microservices, enabling efficient monitoring and troubleshooting. By mapping the complex network of services, Neo4j allows for a better understanding and management of service communications and dependencies, making it easier to identify issues, optimize performance, and ensure seamless integration within a dynamic Kubernetes environment .
What Advantages does Neo4j Offer for Fraud Detection in Cloud Environments?
In cloud environments, Neo4j offers several advantages for fraud detection:
- Real-Time Analysis : Neo4j’s graph model allows for rapid querying and analysis of transactional data, enabling real-time detection of fraudulent activities by identifying unusual patterns and connections.
- Pattern Recognition : Its ability to model and analyze complex relationships helps in recognizing sophisticated fraud patterns that might be missed by traditional methods.
- Anomaly Detection : By examining relationships and behaviors across multiple dimensions, Neo4j can quickly spot anomalies and irregularities in transaction data.
- Scalability : Neo4j scales efficiently in cloud environments, handling large volumes of data and complex queries required for comprehensive fraud detection.
- Flexibility : The schema-free nature of Neo4j allows for easy adaptation to evolving fraud strategies and data models, ensuring ongoing effectiveness in detecting new types of fraud.
How can Neo4j Improve Supply Chain Management and Optimization?
Neo4j improves supply chain management by:
- Providing End-to-End Visibility : Maps relationships across the supply chain to identify bottlenecks and inefficiencies.
- Optimizing Demand and Inventory : Analyzes patterns to balance stock levels and prevent overstock or stockouts.
- Managing Risks : Identifies vulnerabilities and potential risks within the supply chain.
- Enhancing Logistics : Optimizes routes and distribution strategies for efficiency.
- Facilitating Collaboration : Improves coordination and decision-making among supply chain partners.
How Simplyblock Enhances Neo4j Performance in Kubernetes
Simplyblock optimizes Neo4j in Kubernetes environments through: High-performance block storage Scalable storage with zero downtime scalability High availability and durability Cost-effective solutions Seamless Kubernetes integration Enhanced data mobility Advanced data management features
What Specific Performance Improvements can Neo4j Expect with Simplyblock?
Neo4j can benefit from simplyblock’s high-performance block storage, which enhances data access and processing speeds. This leads to improved query performance and faster response times. Additionally, simplyblock’s scalable storage options ensure that performance remains consistent even as data volumes grow.
How does Simplyblock Ensure Data Integrity for Neo4j in Kubernetes?
Simplyblock ensures data integrity for Neo4j by providing high availability and durability through features like automatic erasure coding, sync and async cluster replication, as well as backups. These capabilities safeguard data against loss and ensure that it remains accessible and intact, which is crucial for maintaining data integrity in Kubernetes environments.
Furthermore, simplyblock provides immediate snapshots and copy-on-write clones, enabling instant database forks (or clones) for development and staging environments straight from production.
Can Simplyblock help Reduce Storage Costs for Neo4j Deployments?
Yes, simplyblock helps reduce storage costs for Neo4j deployments by offering cost-effective storage solutions. Its cost optimization strategies allow organizations to manage their storage expenses efficiently, making it a practical choice for controlling storage costs in cloud environments.
Neo4j, coupled with simplyblock’s advanced storage solutions, offers unparalleled performance, scalability, and reliability for graph databases in cloud and Kubernetes environments. By leveraging these technologies, organizations can unlock the full potential of their complex data relationships and drive innovation across various industries.


